










LLaVA-OneVision: A Family of Open Large Multimodal Models (LMMs) for Simplifying Visual Task Transfer


A key goal in the development of AI is the creation of general-purpose assistants utilizing Large Multimodal Models (LMMs). Building AI systems that can work in tandem with people in various settings and with a wide variety of jobs is central to the general-purpose assistant concept. These helpers aren’t confined to just one area of expertise; they’re capable of easily handling customer service, creative projects, personal task management, and even difficult analytical jobs. With the help of LMMs, these assistants can process and react to a wider variety of inputs, increasing their versatility and practicality.
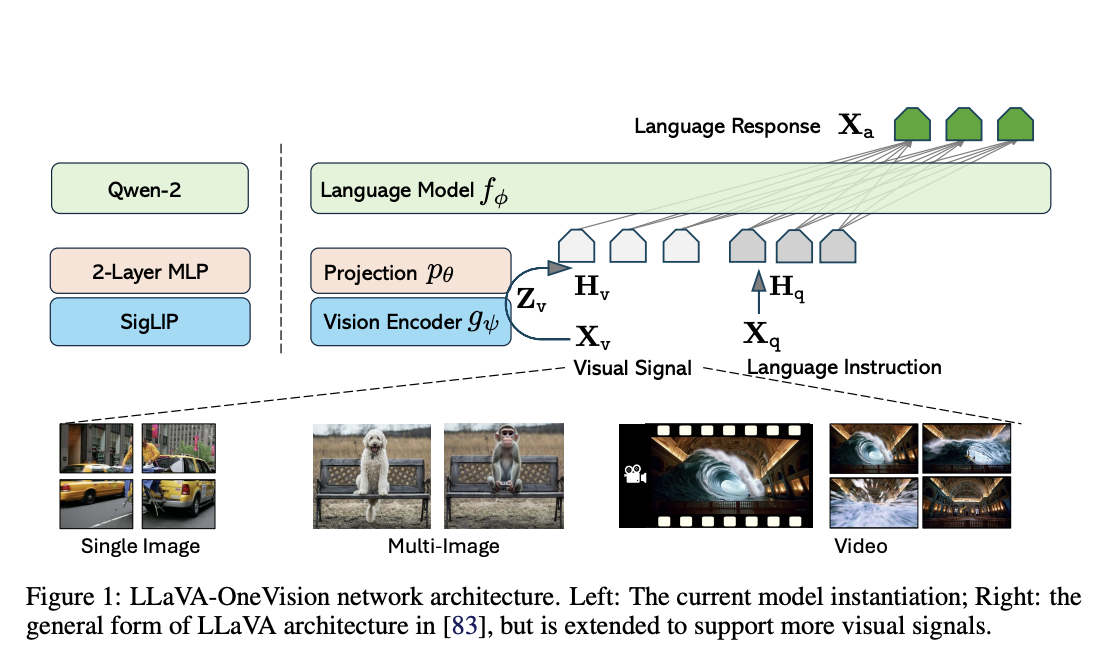
A collaborative effort by ByteDance, NTU, CUHK, and HKUST has led to the development of LLaVA-OneVision, a significant advancement in large vision-and-language assistant (LLaVA) research. This system demonstrates how to construct a model that can understand and execute a wide range of computer vision tasks in real-world scenarios. The use of a basic connection module, which links vision encoders with large language models (LLM), is a cost-efficient recipe that can be beneficial for the entire AI community.
The first LLaVA model shows remarkable multimodal conversation skills, occasionally mimicking GPT-4V behavior on novel images and instructions. LLaVA-1.5 achieves State-of-the-Art (SoTA) performance, meaning it outperforms all other existing models, on hundreds of benchmarks with a data-efficient recipe, greatly expanding and improving the capabilities by including more academic-related instruction data. LLaVA-NeXT takes this quality to its advantage by significantly improving performance through three main methods: AnyRes works with the greatest open-source LLM available then, handles high-resolution photos, and expands high-quality instruction data. The LLaVA series’ minimalist design is carried over into the model architecture with the main objectives of making good use of the pre-trained capabilities of the LLM and visual model and enabling strong data and model scaling behavior.
Modeling of LLaVA-OneVision
Key to the success of visual encoding is the representation of visual signals. The raw pixel resolution and the feature space token count are related to this, as they determine the visual input representation configuration. Both characteristics are scaled to boost performance, particularly on visual detail tasks. The researchers find that scaling resolution is more effective than scaling token numbers in achieving a performance-cost balance, and the researchers propose an AnyRes method with pooling.
The proposed method for data scaling in multimodal pre-training offers a more efficient approach, particularly considering the often poor quality of web-scale public image-text data. By focusing on high-quality knowledge learning within a constrained computing budget, the researchers aim to refine and enhance the information that the pre-trained LLMs and ViTs already hold. To ensure top-notch knowledge acquisition, they carefully examine data from three main areas:
- Data on Detailed Descriptions with Re-Captions. Among open-source LMMs, LLaVA-NeXT-34B stands out for its impressive detailed caption ability. The team created new image captions using the model for the COCO118K, BLIP558K, and CC3M datasets. With a combined total of 3.5 million samples, they made the Re-Captioned Detailed Description Data. Using its early version of the model to produce training data is one way to look at this as a basic effort at self-improvement AI.
- Document and optical character recognition data: The team used the 100K-strong Text Reading subset of the UReader dataset, readily available through PDF rendering. The Document / OCR Data, consisting of 1.1 million samples, was formed by combining this text reading data with the SynDOG EN/CN.
- Data on Chinese and Language: The researchers aimed to increase the model’s capacity in Chinese by using the original ShareGPT4V photos and GPT-4V offered by the Azure API to generate 92K detailed caption data. Their goal was to ensure that the model’s language understanding capacity was balanced, considering the enormous amount of precise caption data employed. From the Evo-Instruct dataset, they extracted 143K samples.
Tuning an LMM to interpret and respond to visual instructions is called visual instruction tuning. The language-visual media (LMM) processes and responds to these instructions, such as text, images, or videos. Interpreting the instructions and making necessary replies requires combining visual understanding with natural language processing. Prior research has shown that LMM capability relies heavily on visual instruction tuning data. Consequently, it is essential and advantageous for the community to maintain a repository of high-quality datasets. The researchers began amassing an uneven data ratio across categories from a wide variety of original sources in order to create a big pool of instruction-tuning datasets. They also use several newly acquired subsets of the datasets from the Cauldron and the Cambrian. Vision, instruction, and response form a three-tiered hierarchy that is used to classify the data.
Academic datasets like VQAv2, GQA, and Visual Genome provide fixed-form data, whereas advanced models like Gemini and GPT-4V/o annotate free-form data. The original responses are preserved for free-form data. When dealing with fixed-form data, though, the team reviews each piece of material by hand and addresses any mistakes in the question-and-answer formats they found. For data types such as multiple-choice, short-answer, and specialized tasks (e.g., OCR), the LLaVA-1.5 prompting technique is followed. This is essential in guiding the model’s behavior to avoid conflicts caused by diverse data sources and ensure proper balancing of QA performance, conversational ability, and reasoning skills in more complex tasks.
One set of instructions is for use in situations with only one image, and the second is for use in all possible vision circumstances. Their previous research provided the groundwork for this separation by demonstrating the interdependence of image and video models; specifically, a more robust image model can better generalize tasks involving multiple photos or videos. Training datasets for single-image tasks also have a far larger amount and better quality than those for movies and multi-image tasks.
The team rigorously segregates three important functionality into three distinct learning stages for the purpose of ablation experiments, in order to enable LLM for multimodal capabilities. In order to train the model, they follow a curriculum learning principle that systematically observes training objectives and examples of progressively more challenging tasks.
- The first step is aligning Language and Images. The objective is to align the visual characteristics with the LLMs’ word embedding space.
- The next step involves High-Quality Knowledge Learning. The researchers suggest considering high-quality knowledge for LMM learning to mix compute efficiency with adding new information to LMMs.
- The researchers then implement Visual Instruction Tuning by categorizing the instruction data into several sets to train LMM to respond appropriately to various visual tasks. Two distinct steps comprise the visual instruction adjustment procedure: (i) Single-Image Training: After being trained on 3.2 million individual images, the model develops a strong ability to follow various directions to do visual tasks with just one image. (ii) Using a combination of video, single-image, and multi-image data, the model is trained using OneVision. At this point, the model can handle more complex scenarios than just those involving a single image. Emergent capabilities are created as it learns to follow instructions to execute tasks in diverse settings and applies that knowledge to other scenarios.
Using LMMs-Eval, the researchers perform consistent and repeatable tests on all benchmarks to assess LLaVA-OneVision models. They mainly report data from original articles so that other prominent LMMs can be fairly compared. They load the models into LMMs-Eval and test them with consistent parameters when results are not available. Unless otherwise noted, they use greedy decoding and 0-shot settings for all of the results. To uncover the proposed paradigm’s efficacy and generalizability, they thoroughly evaluate their LLaVA-OneVision models using various modalities, such as video, audio, and single images. Following the single-image and one-vision stages of model training, refer to the resulting checkpoint as LLaVA-OV (SI) and LLaVA-OV, respectively. Applications ranging from edge devices to cloud serving can use the three available model sizes—0.5B, 7B, and 72B—to accommodate varying performance-throughput trade-offs.
These findings serve as benchmarks for the GPT-4V and GPT-4o. When comparing GPT-4V with GPT-4o on most benchmarks, the largest model, LLaVA-OneVision-72B, produces superior results. The results show that the recipe is effective, which bodes well for future scaling efforts. Nevertheless, there is still a significant chasm in more complicated tasks like visual chat scenarios; the team will leave this for future studies focusing on more robust LLMs, bigger training datasets, and improved preference learning.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
