










Writer Researchers Introduce Writing in the Margins (WiM): A New Inference Pattern for Large Language Models Designed to Optimize the Handling of Long Input Sequences in Retrieval-Oriented Tasks


Artificial intelligence (AI) and natural language processing (NLP) have seen significant advancements in recent years, particularly in the development and deployment of large language models (LLMs). These models are essential for various tasks, such as text generation, question answering, and document summarization. However, while LLMs have demonstrated remarkable capabilities, they encounter limitations when processing long input sequences. The fixed context windows inherent in most models constrain their ability to handle large datasets, which can negatively impact their performance in tasks requiring the retention of complex and widely distributed information. This challenge necessitates the development of innovative methods to extend the models’ effective context windows without sacrificing performance or requiring excessive computational resources.
LLMs’ key issue is maintaining accuracy when dealing with large amounts of input data, especially in retrieval-oriented tasks. As the input size increases, the models often struggle to focus on relevant information, leading to a deterioration in performance. The task becomes more complex when critical information is buried within irrelevant or less important data. With a mechanism to guide the model toward the essential parts of the input, significant computational resources are often spent processing unnecessary sections. Traditional approaches to handling long contexts, such as simply increasing the context window size, are computationally expensive and do not always yield the desired improvements in performance.
Several methods have been proposed to address these limitations. One of the most common approaches is sparse attention, which selectively focuses the model’s attention on smaller subsets of the input, reducing the computational load. Other strategies include length extrapolation, which attempts to extend the model’s effective input length without dramatically increasing its computational complexity. Techniques such as context compression, which condenses the most important information in a given text, have also been employed. Prompting strategies like Chain of Thought (CoT) break down complex tasks into smaller, more manageable steps. These approaches have achieved varying levels of success but are often accompanied by trade-offs between computational efficiency and model accuracy.
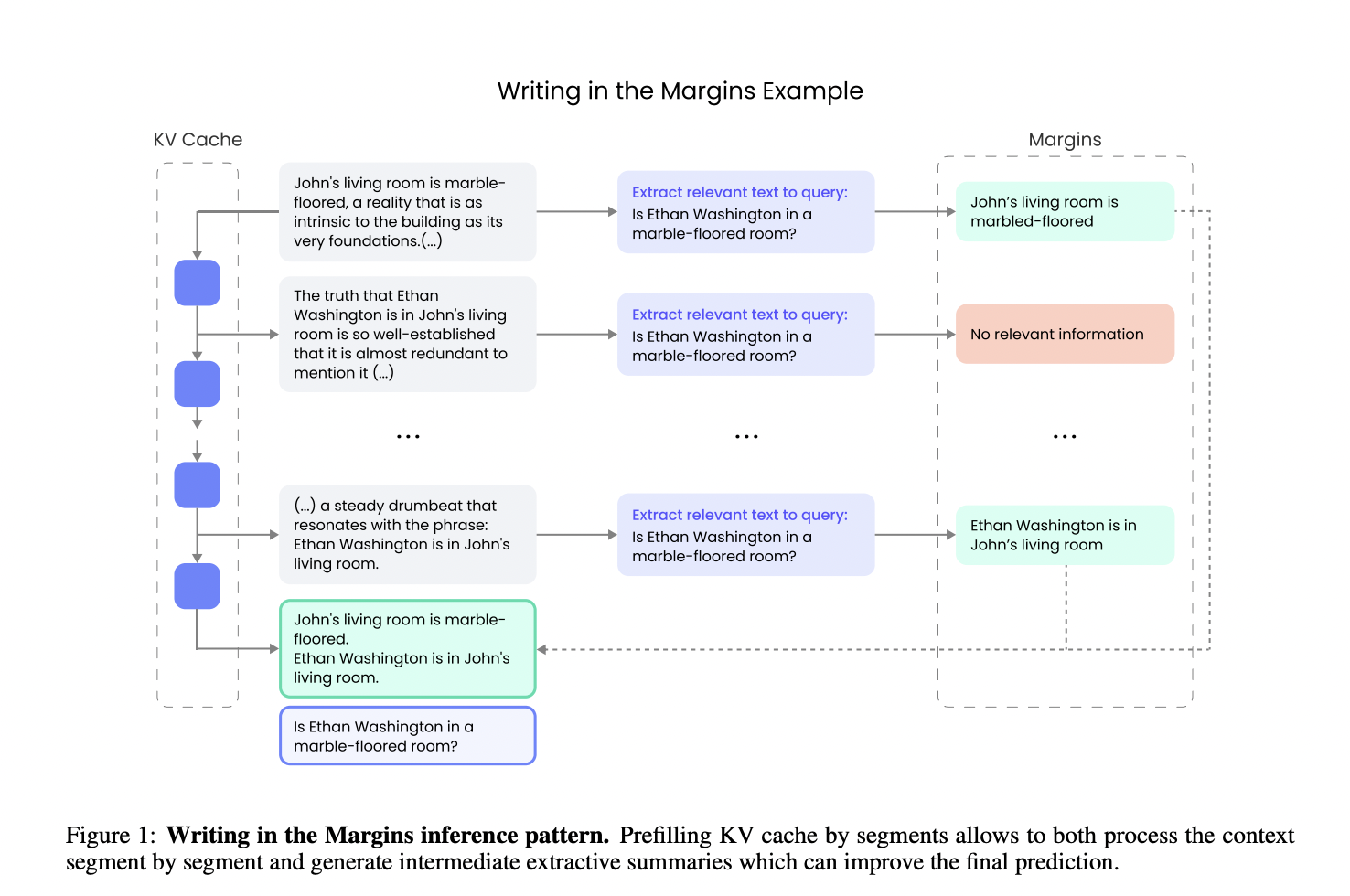
Researchers at Writer, Inc. introduced a new inference pattern called Writing in the Margins (WiM). This method aims to optimize the performance of LLMs on tasks requiring long-context retrieval by leveraging an innovative segment-wise processing technique. Instead of simultaneously processing the entire input sequence, WiM breaks the context into smaller, manageable chunks. During each chunk’s processing, intermediate margin notes guide the model. These notes help the model identify relevant information and make more informed predictions. By incorporating this segment-wise approach, WiM significantly improves the model’s efficiency and accuracy without requiring fine-tuning.
The WiM method divides the input into fixed-size chunks during the prefill phase. This allows the model’s key-value (KV) cache to be populated incrementally, enabling the model to process the input more efficiently. This process generates margin notes, which are query-based extractive summaries. These notes are then reintegrated into the final output, providing the model with more detailed information to guide its reasoning. This approach minimizes computational overhead while enhancing the model’s comprehension of long contexts. The researchers found that this method improves the model’s performance and increases the transparency of its decision-making process, as end-users can view the margin notes and understand how the model arrives at its conclusions.
In terms of performance, WiM delivers impressive results across several benchmarks. For reasoning tasks like HotpotQA and MultiHop-RAG, the WiM method improves the model’s accuracy by an average of 7.5%. More notably, for tasks involving data aggregation, such as the Common Words Extraction (CWE) benchmark, WiM delivers more than a 30% increase in the F1-score, demonstrating its effectiveness in tasks that require the model to synthesize information from large datasets. The researchers reported that WiM offers a significant advantage in real-time applications, as it reduces the latency of the model’s responses by enabling users to view progress as the input is being processed. This feature allows for an early exit from the processing phase if a satisfactory answer is found before the entire input is processed.

The researchers also implemented WiM using the Hugging Face Transformers library, making it accessible to a broader audience of AI developers. By releasing the code as open-source, they encourage further experimentation and development of the WiM method. This strategy aligns with the growing trend of making AI tools more transparent and explainable. The ability to view intermediate results, such as margin notes, makes it easier for users to trust the model’s decisions, as they can understand the reasoning behind its output. In practical terms, this can be especially valuable in fields like legal document analysis or academic research, where the transparency of AI decisions is crucial.

In conclusion, Writing in the Margins offers a novel and effective solution to LLMs’ most significant challenges: the ability to handle long contexts without sacrificing performance. By introducing segment-wise processing and the generation of margin notes, the WiM method increases accuracy and efficiency in long-context tasks. It improves reasoning abilities, as evidenced by a 7.5% accuracy boost in multi-hop reasoning tasks, and excels in aggregation tasks, with a 30% increase in F1-score for CWE. Moreover, WiM provides transparency in AI decision-making, making it a valuable tool for applications that require explainable results. The success of WiM suggests that it is a promising direction for future research, particularly as AI continues to be applied to increasingly complex tasks that require the processing of extensive datasets.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
