










This AI Paper from China Introduces a Reward-Robust Reinforcement Learning from Human Feedback RLHF Framework for Enhancing the Stability and Performance of Large Language Models
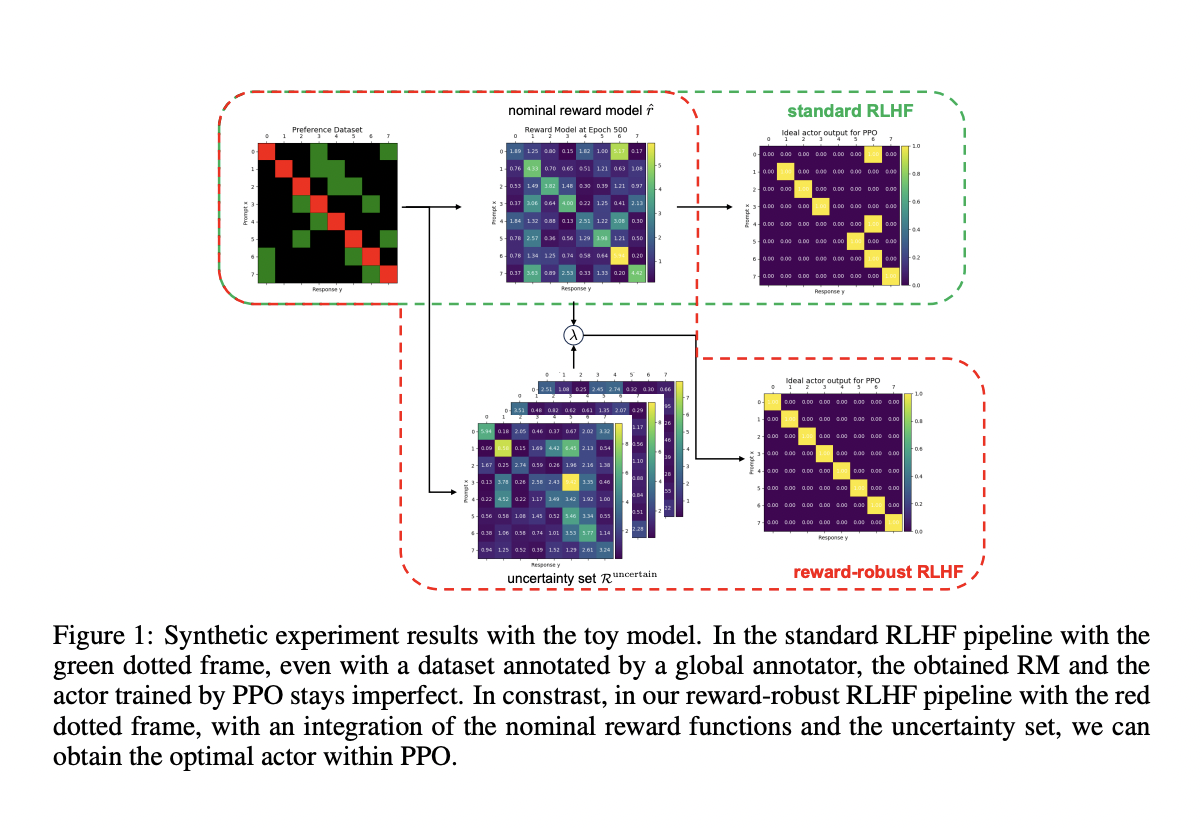


Reinforcement Learning from Human Feedback (RLHF) has emerged as a vital technique in aligning large language models (LLMs) with human values and expectations. It plays a critical role in ensuring that AI systems behave in understandable and trustworthy ways. RLHF enhances the capabilities of LLMs by training them based on feedback that allows models to produce more helpful, harmless, and honest outputs. This approach is widely utilized in developing AI tools ranging from conversational agents to advanced decision-support systems, aiming to integrate human preferences directly into model behavior.
Despite its importance, RLHF faces several fundamental challenges. One of the primary issues is the instability and inherent imperfections in the reward models that guide the learning process. These reward models often misrepresent human preferences due to biases present in the training data. Such biases can lead to problematic issues like reward hacking, where models exploit loopholes in the reward function to gain higher rewards without actually improving task performance. Furthermore, reward models often suffer from overfitting and underfitting, which means they fail to generalize well to unseen data or capture essential patterns. Consequently, this misalignment between the model’s behavior and true human intent hinders the performance and stability of RLHF.
Despite numerous attempts to address these issues, the urgency for a robust RLHF framework remains. Conventional methods, including Proximal Policy Optimization (PPO) and Maximum Likelihood Estimation (MLE) for training reward models, have shown promise but have not fully resolved the inherent uncertainties and biases in reward models. Recent approaches, such as contrastive rewards or ensembles of reward models, have attempted to mitigate these issues. However, they still struggle to maintain stability and alignment in complex real-world scenarios. The need for a framework that can robustly manage these challenges and ensure reliable learning outcomes is more pressing than ever.
Researchers from the Tsinghua University and Baichuan AI have a new reward-robust RLHF framework. This innovative framework utilizes Bayesian Reward Model Ensembles (BRME) to capture and manage the uncertainty in reward signals effectively. Using BRME allows the framework to incorporate multiple perspectives into the reward function, thus reducing the risk of misalignment and instability. The proposed framework is designed to balance performance and robustness, making it more resistant to errors and biases. By integrating BRME, the system can select the most reliable reward signals, ensuring more stable learning despite imperfect or biased data.
The methodology of this proposed framework is centered on a multi-head reward model. Each head in the model outputs the mean and standard deviation of a Gaussian distribution, which represents the reward. This multi-head approach captures the mean reward values and quantifies the confidence in each reward signal. During training, the head with the lowest standard deviation is selected as the nominal reward function, effectively filtering out unreliable reward signals. The framework leverages Mean Square Error (MSE) loss for training, ensuring that the output’s standard deviation accurately reflects the model’s confidence. Unlike traditional RLHF methods, this approach prevents the model from relying too heavily on any single reward signal, thus mitigating the risk of reward hacking or misalignment.
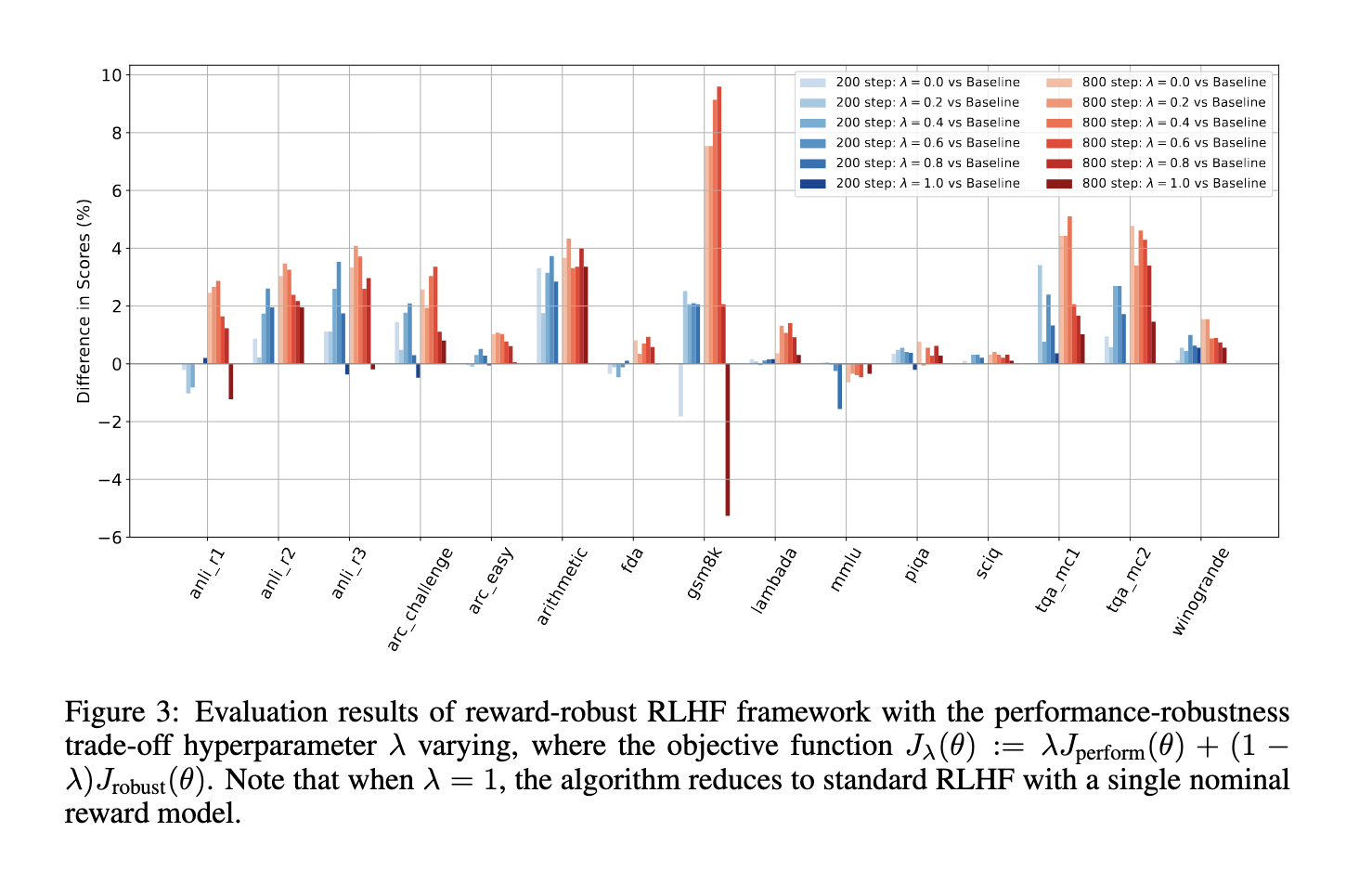
The proposed reward-robust RLHF framework has demonstrated impressive performance, consistently outperforming traditional RLHF methods across various benchmarks. The research team comprehensively evaluated their framework on 16 widely used datasets, including ARC, LAMBADA, and MMLU, covering areas like general knowledge, reasoning, and numerical computation. The results were compelling, showing that the proposed method achieved an average accuracy increase of about 4% compared to conventional RLHF. Moreover, when the reward uncertainty was integrated into the training process, the new method showed a performance gain of 2.42% and 2.03% for specific tasks, underscoring its ability to handle biased and uncertain reward signals effectively. For instance, in the LAMBADA dataset, the proposed method significantly improved performance stability, reducing the fluctuation seen in traditional methods by 3%. This not only enhances performance but also ensures long-term stability during extended training periods, a key advantage of the framework.
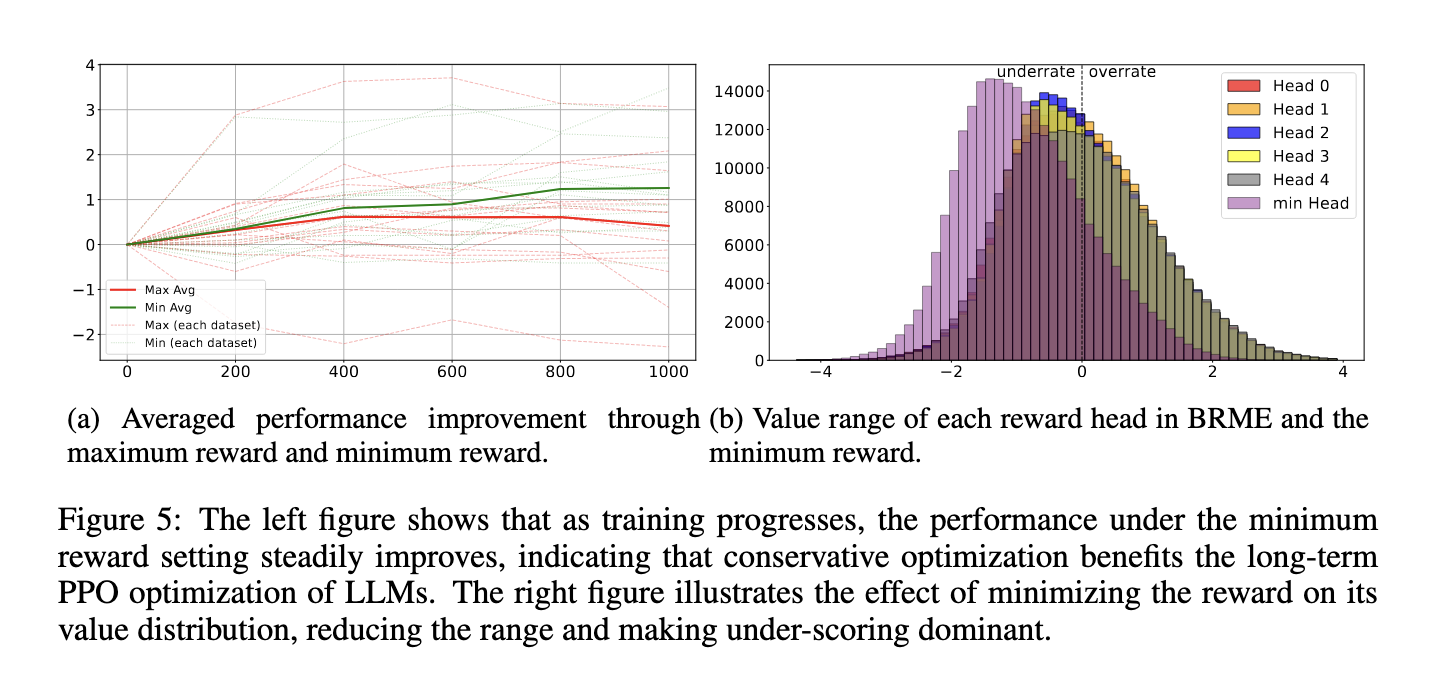
The reward-robust RLHF framework’s ability to resist performance degradation, often caused by unreliable reward signals, is a significant achievement. In scenarios where traditional RLHF methods struggle, the proposed method maintains or even improves model performance, demonstrating its potential for real-world applications where reward signals are rarely perfect. This stability is crucial for deploying AI systems that can adapt to changing environments and maintain high performance under various conditions, underscoring the practical value of the framework.
Overall, the research addresses fundamental challenges in the RLHF process by introducing a robust framework stabilizing the learning process in large language models. By balancing nominal performance with robustness, this novel method offers a reliable solution to persistent issues like reward hacking and misalignment. The proposed framework, developed by Tsinghua University and Baichuan AI, holds promise for advancing the field of AI alignment and paving the way for safer and more effective AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit.
We invite startups, companies, and research institutions working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.