










Decoding Similarity: A Framework for Analyzing Neural and Model Representations
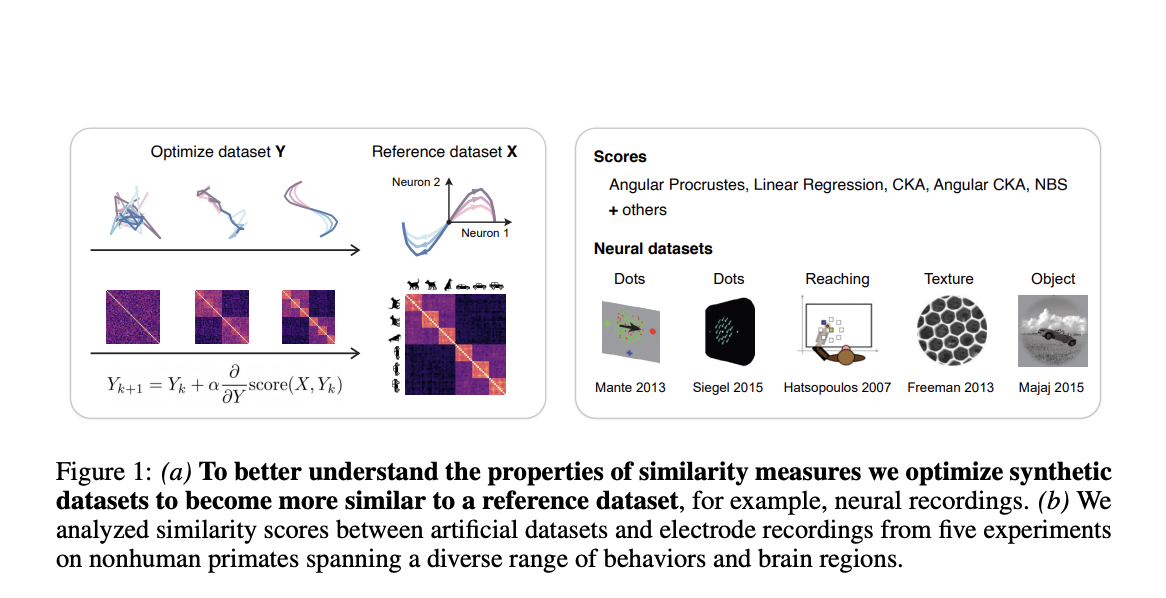


To determine if two biological or artificial systems process information similarly, various similarity measures are used, such as linear regression, Centered Kernel Alignment (CKA), Normalized Bures Similarity (NBS), and angular Procrustes distance. Despite their popularity, the factors contributing to high similarity scores and what defines a good score remain to be determined. These metrics are commonly applied to compare model representations with brain activity, aiming to find models with brain-like features. However, whether these measures capture the relevant computational properties is uncertain, and clearer guidelines are needed for choosing the right metric for each context.
Recent work has highlighted the need for practical guidance on selecting representational similarity measures, which this study addresses by offering a new evaluation framework. The approach optimizes synthetic datasets to maximize their similarity to neural recordings, allowing for a systematic analysis of how different metrics prioritize various data features. Unlike previous methods that rely on pre-trained models, this technique starts with unstructured noise, revealing how similarity measures shape task-relevant information. The framework is model-independent and can be applied to different neural datasets, identifying consistent patterns and fundamental properties of similarity measures.
Researchers from MIT, NYU, and HIH Tübingen developed a tool to analyze similarity measures by optimizing synthetic datasets to maximize their similarity to neural data. They found high similarity scores do not necessarily reflect task-relevant information, especially in measures like CKA. Different metrics prioritize distinct aspects of the data, such as principal components, which can impact their interpretation. Their study also highlights the lack of consistent thresholds for similarity scores across datasets and measures, emphasizing caution when using these metrics to assess alignment between models and neural systems.
To measure the similarity between two systems, feature representations from a brain area or model layer are compared using similarity scores. Datasets X and Y are analyzed and reshaped if temporal dynamics are involved. Various methods, like CKA, Angular Procrustes, and NBS, are used to calculate these scores. The process involves optimizing synthetic datasets (Y) to resemble reference datasets (X) by maximizing their similarity scores. Throughout optimization, task-relevant information is decoded from the synthetic data, and the principal components of X are evaluated to determine how well Y captures them.
The research examines what defines an ideal similarity score by analyzing five neural datasets, highlighting that optimal scores depend on the chosen measure and the dataset. In one dataset, Mante 2013, good scores range significantly from below 0.5 to close to 1. It also shows that high similarity scores, especially in CKA and linear regression, do not always reflect that task-related information is encoded similarly to neural data. Some optimized datasets even surpass original data, possibly due to advanced denoising techniques, though further research is needed to validate this.
The study highlights significant limitations in commonly used similarity measures, such as CKA and linear regression, for comparing models and neural datasets. High similarity scores do not necessarily indicate that synthetic datasets effectively encode task-relevant information akin to neural data. The findings show that the quality of similarity scores depends on the specific measure and dataset, with no consistent threshold for what constitutes a “good” score. The research introduces a new tool to analyze these measures and suggests that practitioners should interpret similarity scores carefully, emphasizing the importance of understanding the underlying dynamics of these metrics.
Check out the Paper, Project, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
