










Researchers from China Unveil ImageReward: A Groundbreaking Artificial Intelligence Approach to Optimizing Text-to-Image Models Using Human Preference Feedback


Recent years have seen tremendous developments in text-to-image generative models, including auto-regressive and diffusion-based methods. These models can produce high-fidelity, semantically relevant visuals on various topics when given the right language descriptions (i.e., prompts), sparking considerable public interest in their possible uses and effects. Despite the advancements, current self-supervised pre-trained generators still have a long way to go. Since the pre-training distribution is noisy and different from the actual user-prompt distributions, aligning models with human preferences is a major difficulty.
The resulting difference causes several well-known problems in the photographs, including but not limited to:
• Text-image alignment errors: as seen in Figure 1(a)(b), including failing to portray all the numbers, qualities, properties, and connections of objects stated in text prompts.
• Body Problem: Displaying limbs or other twisted, missing, duplicated, or aberrant human or animal body parts, as shown in Figure 1(e)(f).
• Human Aesthetic: departing from the typical or mainstream aesthetic preferences of humans, as seen in Figure 1(c)(d).
• Toxicity and Biases: including offensive, violent, sexual, discriminatory, unlawful, or upsetting content, as seen in Figure 1(f).
Figure 1: (Upper) Images from the top-1 generation out of 64 generations as determined by several text-image scorers.(Lower) 1-shot creation utilizing ImageReward as feedback following ReFL training. ImageReward selection or ReFL training improves text coherence and human preference for images. Italic indicates style or function, whereas bold generally implies substance in prompts (from actual users, abridged).
However, more than merely enhancing model designs and pre-training data is required to overcome these pervasive issues. Researchers have used reinforcement learning from human feedback (RLHF) in natural language processing (NLP) to direct big language models toward human preferences and values. The method depends on learning a reward model (RM) using enormous expert-annotated model output comparisons to capture human preference. Despite its effectiveness, the annotation process might be expensive and difficult because it takes months to define labeling criteria, hire and educate experts, validate replies, and generate the RM.
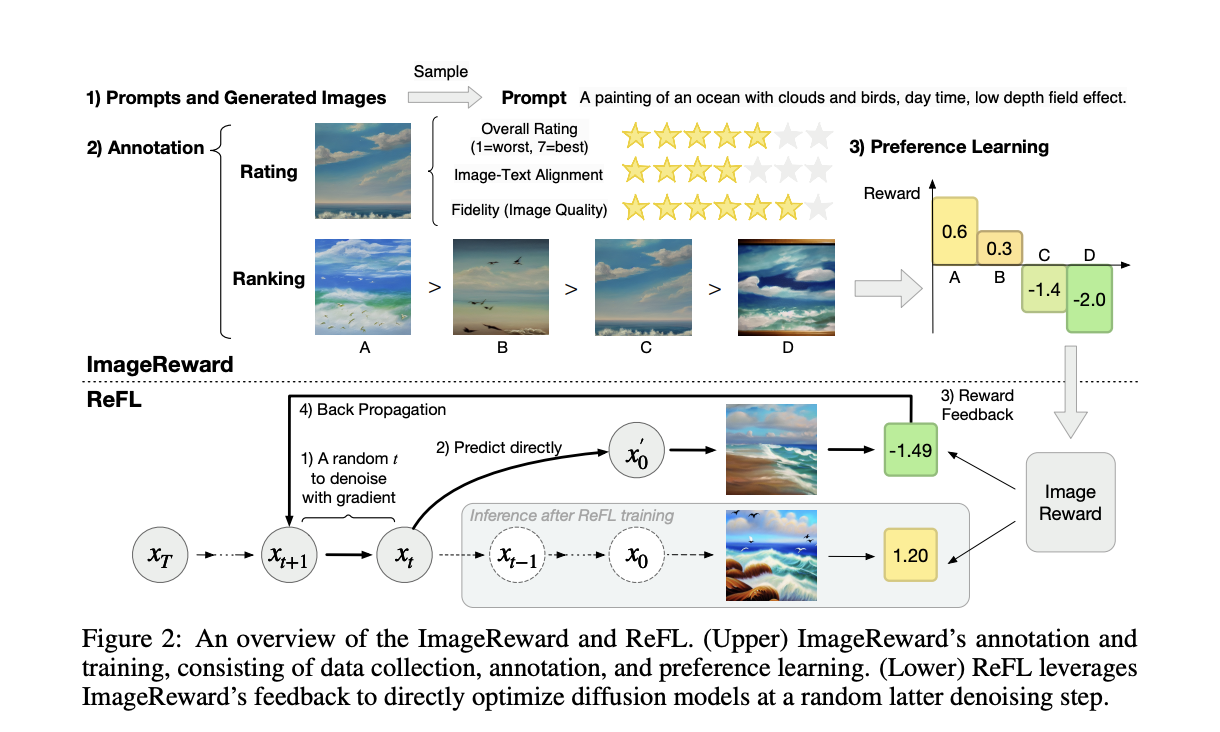
Researchers from Tsinghua University and Beijing University of Posts and Telecommunications present and release the first general-purpose text-to-image human preference RM ImageReward in recognition of the significance of addressing these difficulties in generative models. ImageReward is trained and evaluated on 137k pairs of expert comparisons based on actual user prompts and corresponding model outputs. They continue to research the direct optimization strategy ReFL for enhancing diffusion generative models based on the effort.
• They develop a pipeline for text-to-image human preference annotation by methodically identifying its difficulties, establishing standards for quantitative evaluation and annotator training, enhancing labeling efficiency, and ensuring quality validation. They create the pipeline-based text-to-image comparison dataset to train the ImageReward model.
• Through in-depth study and testing, they show that ImageReward beats other text-image scoring techniques, such as CLIP (by 38.6%), Aesthetic (by 39.6%), and BLIP (by 31.6%), in terms of understanding human preference in text-to-image synthesis. Additionally, ImageReward has demonstrated a considerable reduction in the aforementioned problems, offering insightful information about incorporating human desire into generative models.
• They assert that the automated text-to-image assessment measure ImageReward could be useful. ImageReward aligns consistently with human preference ranking and exhibits superior distinguishability across models and samples compared to FID and CLIP scores on prompts from actual users and MS-COCO 2014.
• For fine-tuning diffusion models concerning human preference scores, they suggest Reward Feedback Learning (ReFL). Since diffusion models don’t provide any probability for their generations, their special insight into ImageReward’s quality identifiability at later denoising phases enables direct feedback learning on those models. ReFL has been extensively evaluated automatically and manually, demonstrating its advantages over other methods, including data augmentation and loss reweighing.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
