










AWS Researchers Propose Panda: A New Machine Learning Framework to Provide Context Grounding to Pre-Trained LLMs


Debugging performance issues in databases is challenging, and there is a need for a tool that can provide useful and in-context troubleshooting recommendations. Large Language Models (LLMs) like ChatGPT can answer many questions but often provide vague or generic recommendations for database performance queries.
While LLMs are trained on vast amounts of internet data, their generic recommendations lack context and the multi-modal analysis required for debugging. Retrieval Augmented Generation (RAG) is proposed to enhance prompts with relevant information, but applying LLM-generated recommendations in real databases raises concerns about trust, impact, feedback, and risk. Thus, What are the essential building blocks needed for safely deploying LLMs in production for accurate, verifiable, actionable, and useful recommendations? is an open and ambiguous question.
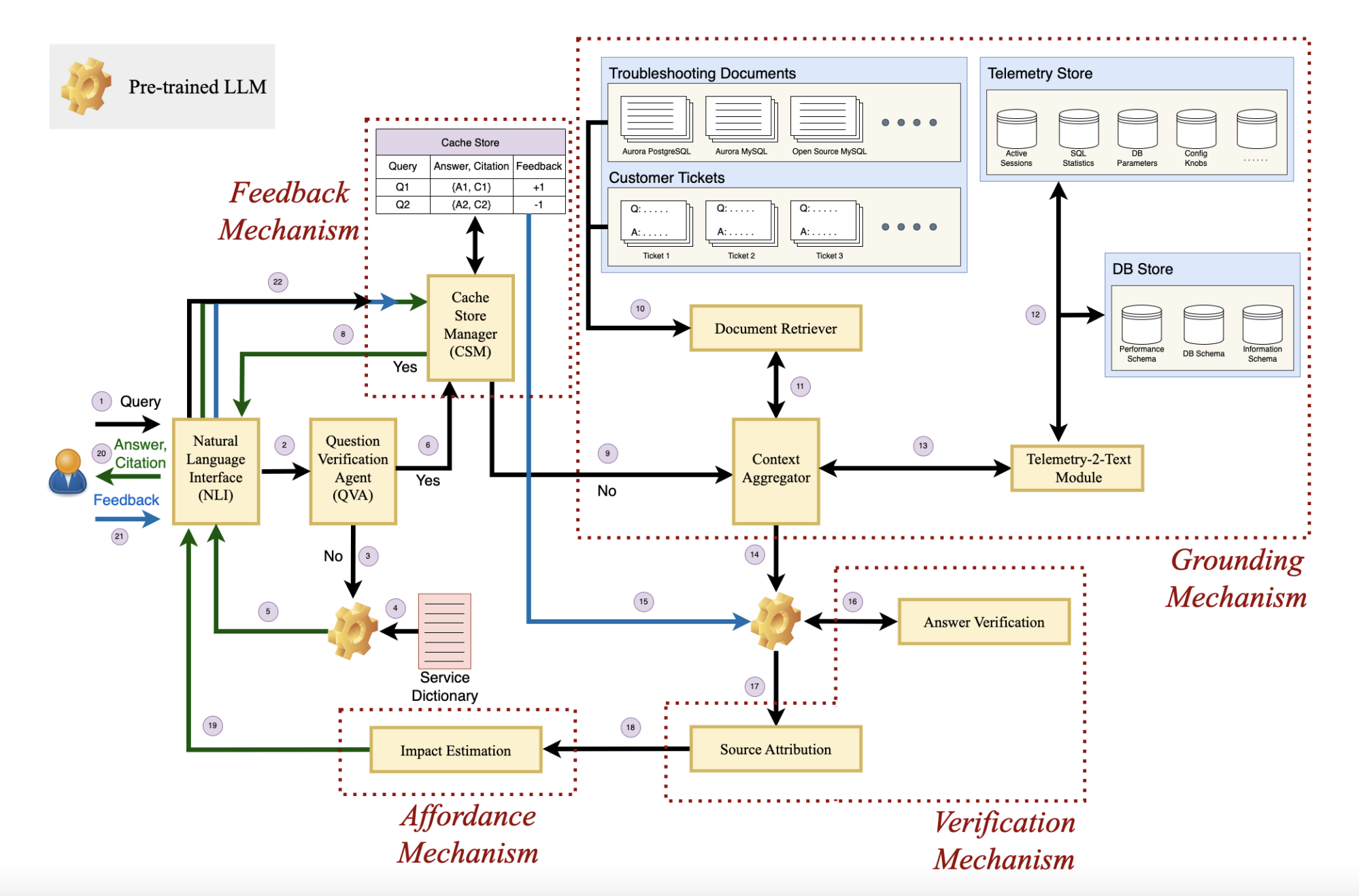
Researchers from AWS AI Labs and Amazon Web Services have proposed Panda, which aims to provide context grounding to pre-trained LLMs for generating more useful and in-context troubleshooting recommendations for database performance debugging. Panda has several key components: grounding, verification, affordability, and feedback.
The Panda system comprises five components: Question Verification Agent filters queries for relevance, the Grounding Mechanism extracts global and local contexts, the Verification Mechanism ensures answer correctness, the Feedback Mechanism incorporates user feedback, and the Affordance Mechanism estimates the impact of recommended fixes. Panda uses Retrieval Augmented Generation for contextual query handling, employing embeddings for similarity searches. Telemetry metrics and troubleshooting docs provide multi-modal data for better understanding and more accurate recommendations, addressing the contextual challenges of database performance debugging.
In a small experimental study comparing Panda, utilizing GPT-3.5, with GPT-4 for real-world problematic database workloads, Panda demonstrated superior reliability and usefulness according to Database Engineers’ evaluations. Intermediate and Advanced DBEs found Panda’s answers more trustworthy and useful due to source citations and correctness grounded in telemetry and troubleshooting documents. Beginner DBEs also favored Panda but highlighted concerns about specificity. Statistical analysis using a two-sample T-Test showed the statistical superiority of Panda over GPT-4.
In conclusion, the researchers introduce Panda, an innovative system for autonomous database debugging using NL agents. Panda excels in identifying and rejecting irrelevant queries, constructing meaningful multi-modal contexts, estimating impact, offering citations, and learning from feedback. It emphasizes the significance of addressing open research questions encountered during its development and invites collaboration from the database and systems communities to reshape the database debugging process collectively. The system aims to redefine and enhance the overall approach to debugging databases.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
