










Check Out This New AI System Called Student of Games (SoG) that is capable of both Beating Humans at a Variety of Games and Learning to Play New Ones


There is a long tradition of using games as AI performance indicators. Search and learning-based approaches performed well in various perfect information games, while game theory-based methods performed well in a few imperfect information poker variations. By combining directed search, self-play learning, and game-theoretic reasoning, the AI researchers from EquiLibre Technologies, Sony AI, Amii and Midjourney, working with Google’s DeepMind project, propose Student of Games, a general-purpose algorithm that unifies earlier efforts. With its high empirical performance in big perfect and imperfect information games, Student of Games is a significant step toward developing universal algorithms applicable in any setting. With increasing computational and approximation power, they show that Student of Games is robust and eventually achieves flawless play. Student of Games performs strongly in chess and Go, beats the strongest openly available agent in heads-up no-limit Texas hold ’em poker, and defeats the state-of-the-art agent in Scotland Yard. This imperfect information game illustrates the value of guided search, learning, and game-theoretic reasoning.
To demonstrate how far artificial intelligence has progressed, a computer was taught to play a board game and then improved to the point where it could beat humans at the game. With this latest study, the team has made significant progress toward creating artificial general intelligence, where a computer can perform tasks previously thought impossible for a machine.
Most board game-playing computers have been designed to play just one game, like chess. By designing and constructing such systems, scientists have created a form of constrained artificial intelligence. The researchers behind this new project have developed an intelligent system that can compete in games that require a wide range of abilities.
What is SoG – “Student Of Games”?
Combining search, learning, and game-theoretic analysis into a single algorithm, SoG has many practical applications. SoG comprises a GT-CFR technique for learning CVPNs and sound self-play. In particular, SoG is a reliable algorithm for optimal and suboptimal information games: SoG is guaranteed to generate a better approximation of minimax-optimal techniques as computer resources improve. This discovery is also proven empirically in Leduc poker, where additional search leads to test-time approximation refinement, unlike any pure RL systems that do not use search.
Why is SoG so effective?
SoG employs a technique called growing-tree counterfactual regret minimization (GT-CFR), which is a form of local search that may be performed at any time and involves the non-uniform construction of subgames to increase the weight of the subgames with which the most important future states are associated. Further, SoG employs a learning technique called sound self-play, which trains value-and-policy networks based on game results and recursive sub-searches applied to scenarios discovered in earlier searches. As a significant step toward universal algorithms that can be learned in any situation, SoG exhibits good performance across multiple problem domains with perfect and imperfect information. In inferior information games, standard search applications face well-known issues.
Summary of Algorithms
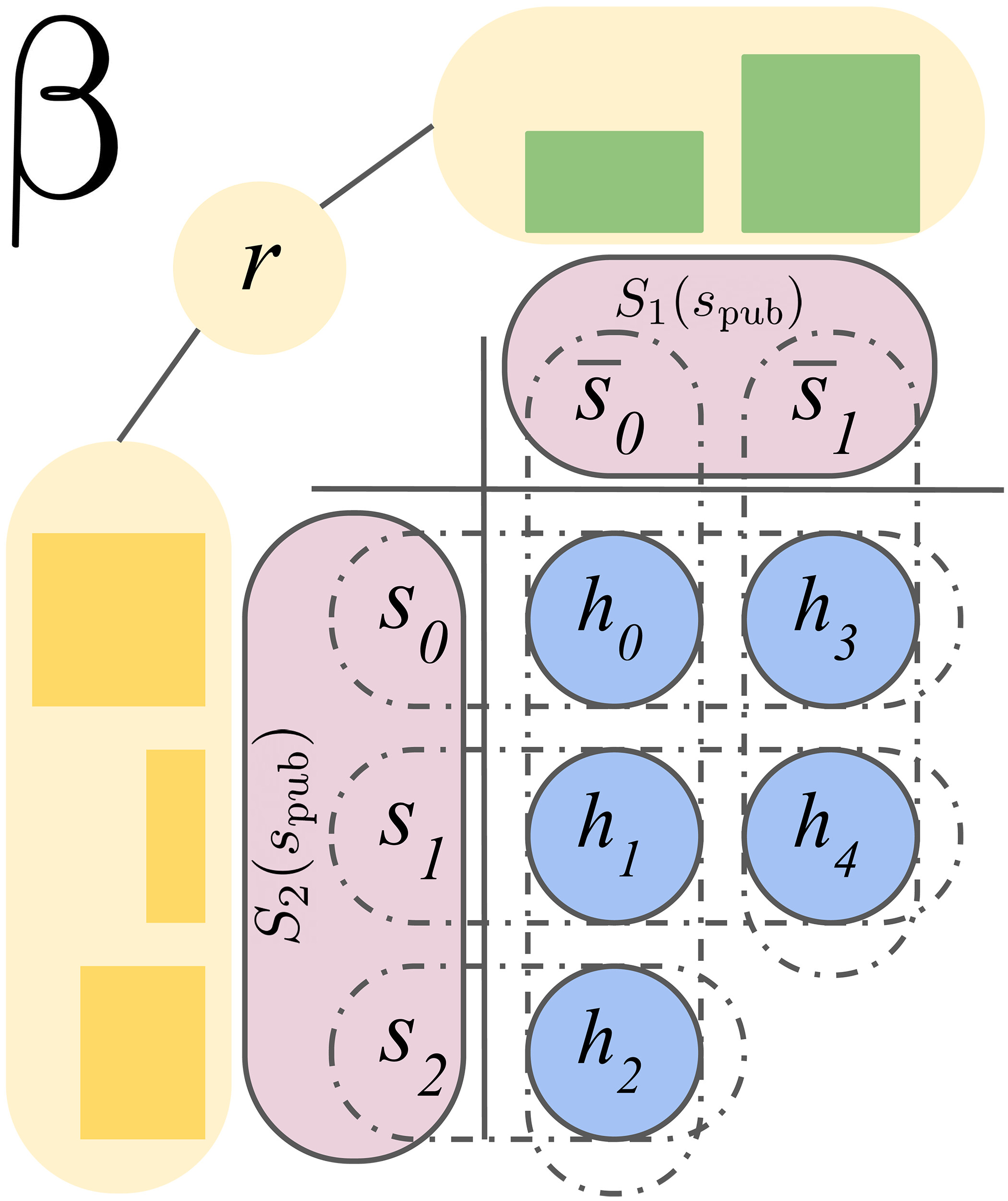
The SoG method uses acoustic self-play to instruct the agent: When making a choice, each player uses a well-tuned GT-CFR search coupled with a CVPN to produce a policy for the current state, which is then utilized to sample an action randomly. GT-CFR is a two-stage process that begins with the present public state and ends with a mature tree. The current public tree’s CFR is updated during the regret update phase. During the expansion phase, new general forms are added to the tree using expansion trajectories based on simulation. GT-CFR iterations comprise one regret updating phase run and one expansion phase run.
Training data for the value and policy networks is generated throughout the self-play process: search queries (public belief states queried by the CVPN during the GT-CFR regret update phase) and full-game trajectories. The search queries must be resolved to update the value network based on counterfactual value targets. The policy network can be adjusted to targets derived from the full-game trajectories. The actors create the self-play data (and answer inquiries) while the trainers discover and implement new networks and occasionally refresh the actors.
Some Limitations
- The use of betting abstractions in poker might be abandoned in favor of a generic action-reduction policy for vast action spaces.
- A generative model that samples world states and works on the sampled subset could approximate SoG, which currently necessitates enumerating each public state’s information, which can be prohibitively expensive in some games.
- Strong performance in challenge domains often requires a large amount of computational resources; an intriguing question is whether or not this level of performance is attainable with fewer resources.
The research team believes it has the potential to thrive at other sorts of games due to its ability to teach itself how to play nearly any game, and it has already beaten rival AI systems and humans at Go, chess, Scotland Yard, and Texas Hold ’em poker.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
