










Golden Retriever: An Agentic Retrieval Augmented Generation (RAG) Tool for Browsing and Querying Large Industrial Knowledge Stores More Effectively


Large Language Models (LLMs) have demonstrated remarkable effectiveness in addressing generic questions. An LLM can be fine-tuned using the company’s proprietary documents to utilize it for a company’s specific needs. However, this process is computationally intensive and has several limitations. Fine-tuning may lead to issues such as the Reversal Curse, where the model’s ability to generalize to new knowledge is hindered.
Retrieval Augmented Generation (RAG) offers a more adaptable and scalable method for managing substantial document collections as an alternative. An LLM, a document database, and an embedding model comprise RAG’s three primary parts. It preserves semantic information by embedding document segments into a database during the offline preparation stage.
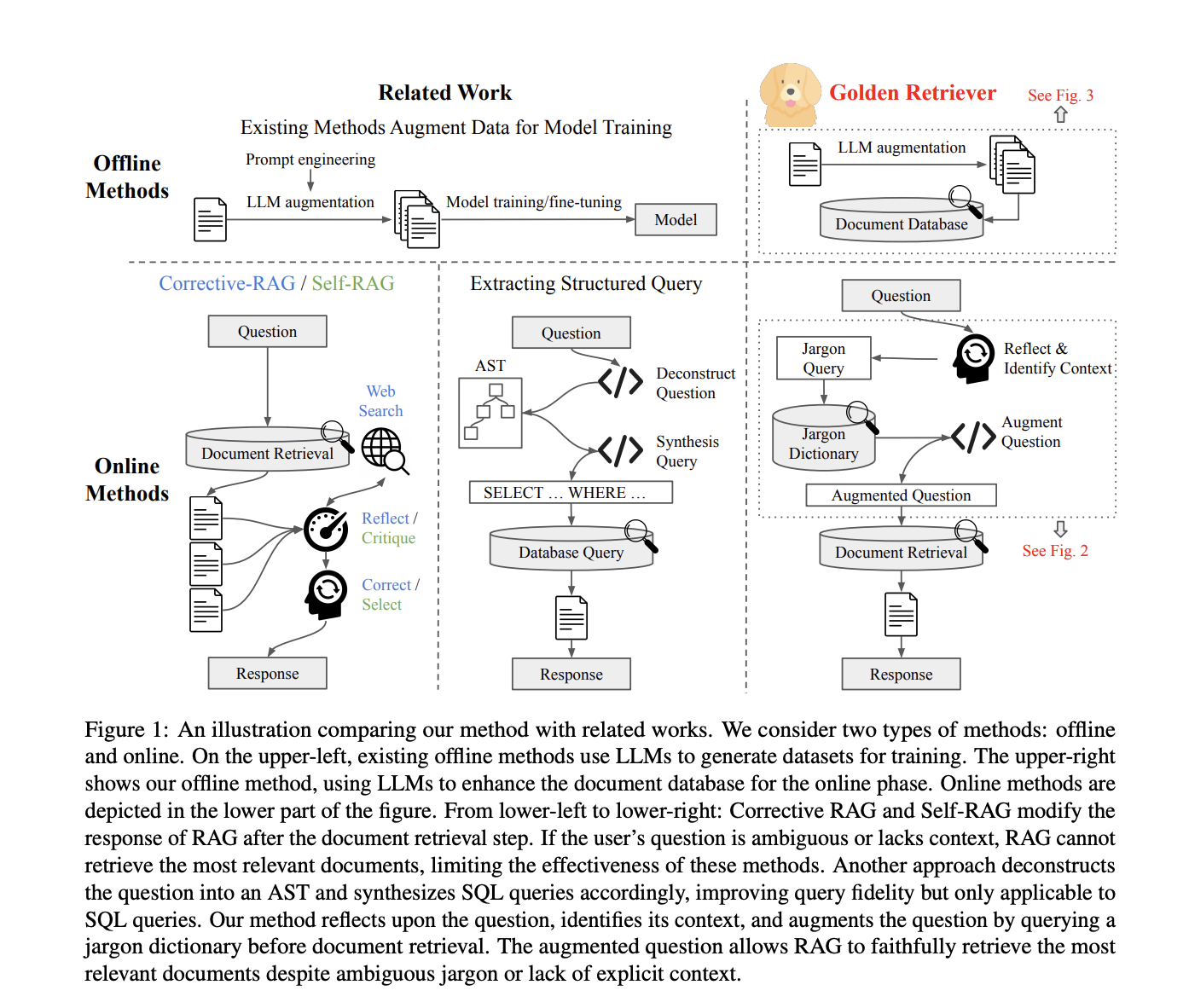
However, RAG has a unique set of difficulties despite its benefits, especially when dealing with domain-specific papers. Domain-specific jargon and acronyms, which might only be found in proprietary papers, are a significant problem since they can cause the LLM to misunderstand or have hallucinations. Even techniques like Corrective RAG and Self-RAG suffer when user queries contain unclear technical terms, which can lead to the retrieval of pertinent documents being unsuccessful.
In a recent research, a team of researchers introduced the Golden Retriever framework, a tool created to browse and query large industrial knowledge stores more effectively. Golden Retriever presents a unique strategy that improves the question-answering procedure prior to document retrieval. The primary innovation of Golden Retriever is its reflection-based question enhancement phase, which is carried out prior to any document retrieval.
The first step in this procedure is to find any jargon or acronyms in the user’s input query. After these terms are found, the framework examines the context in which they are employed to clarify their meaning. This is important because general-purpose models may misunderstand or misinterpret the specialized language used in technical fields.
Golden Retriever uses an extensive approach. It starts by extracting all of the acronyms and jargon from the input question and listing them. After that, the system consults a pre-compiled list of contexts pertinent to the domain to ascertain the question’s context. Subsequently, a jargon dictionary is queried to retrieve more detailed definitions and descriptions of the phrases that have been detected. By clearing up any ambiguities and giving a clear context, this improved comprehension of the question guarantees that the RAG framework will select documents that are most relevant to the user’s query when it gets them.
Three open-source LLMs have been used to evaluate Golden Retriever on a domain-specific question-answer dataset, demonstrating its effectiveness. According to these assessments, Golden Retriever performs better than conventional techniques and provides a reliable option for integrating and querying big industrial knowledge stores. It greatly improves the accuracy and relevance of the information retrieved by ensuring that the context and meaning of domain-specific jargon are understood before document retrieval. This makes it a valuable tool for organizations with extensive and specialized knowledge bases.
The team has summarized their primary contributions as follows.
- The team has acknowledged and tackled the challenges posed by using LLMs to query knowledge bases in practical applications, especially with regard to context interpretation and handling of domain-specific jargon.
- An improved version of the RAG framework has been presented. With this method, which includes a reflection-based question augmentation stage prior to document retrieval, RAG can more reliably find pertinent documents even in situations where the terminology may be unclear or the context may be inadequate.
- Three separate open-source LLMs have been used to thoroughly assess Golden Retriever’s performance. The experiments on a domain-specific question-answer dataset have shown that Golden Retriever is significantly more accurate and effective than baseline algorithms at extracting relevant information from large-scale knowledge libraries.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.

