










Google AI Releases Gemma 3n: A Compact Multimodal Model Built for Edge Deployment


Google has introduced Gemma 3n, a new addition to its family of open models, designed to bring large multimodal AI capabilities to edge devices. Built from the ground up with a mobile-first design philosophy, Gemma 3n can process and understand text, images, audio, and video on-device, without relying on cloud compute. This architecture represents a significant leap in the direction of privacy-preserving, real-time AI experiences across devices like smartphones, wearables, and smart cameras.
Key Technical Highlights of Gemma 3n
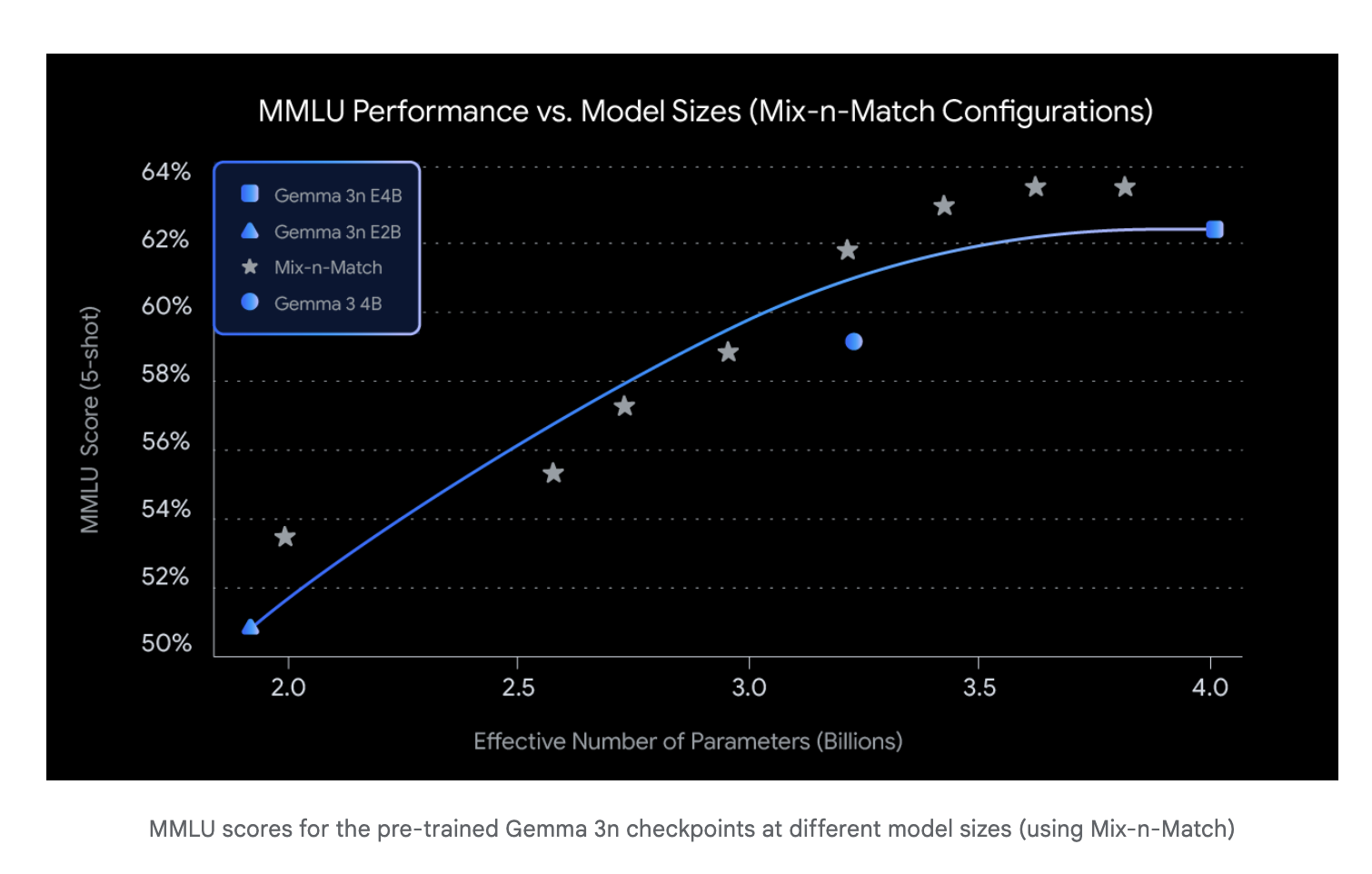
The Gemma 3n series includes two versions: Gemma 3n E2B and Gemma 3n E4B, optimized to deliver performance on par with traditional 5B and 8B parameter models respectively, while utilizing fewer resources. These models integrate architectural innovations that drastically reduce memory and power requirements, enabling high-quality inference locally on edge hardware.
- Multimodal Capabilities: Gemma 3n supports multimodal understanding in 35 languages, and text-only tasks in over 140 languages.
- Reasoning Proficiency: The E4B variant breaks a 1300 score barrier on academic benchmarks like MMLU, a first for sub-10B parameter models.
- High Efficiency: The model’s compact architecture allows it to operate with less than half the memory footprint of comparable models, while retaining high quality across use cases.
Model Variants and Performance
- Gemma 3n E2B: Designed for high efficiency on devices with limited resources. Performs like a 5B model while consuming less energy.
- Gemma 3n E4B: A high-performance variant that matches or exceeds 8B-class models in benchmarks. It is the first model under 10B to surpass a 1300 score on MMLU.

Both models are fine-tuned for:
- Complex math, coding, and logical reasoning tasks
- Advanced vision-language interactions (image captioning, visual Q&A)
- Real-time speech and video understanding

Developer-Centric Design and Open Access
Google has made Gemma 3n available through platforms like Hugging Face with preconfigured training checkpoints and APIs. Developers can easily fine-tune or deploy the models across hardware, thanks to compatibility with TensorFlow Lite, ONNX, and NVIDIA TensorRT.
The official developer guide provides support for implementing Gemma 3n into diverse applications, including:
- Environment-aware accessibility tools
- Intelligent personal assistants
- AR/VR real-time interpreters
Applications at the Edge
Gemma 3n opens new possibilities for edge-native intelligent applications:
- On-device accessibility: Real-time captioning and environment-aware narration for users with hearing or vision impairments
- Interactive education: Apps that combine text, images, and audio to enable rich, immersive learning experiences
- Autonomous vision systems: Smart cameras that interpret motion, object presence, and voice context without sending data to the cloud
These features make Gemma 3n a strong candidate for privacy-first AI deployments, where sensitive user data never leaves the local device.

Training and Optimization Insights
Gemma 3n was trained using a robust, curated multimodal dataset combining text, images, audio, and video sequences. Leveraging data-efficient fine-tuning strategies, Google ensured that the model maintained high generalization even with a relatively smaller parameter count. Innovations in transformer block design, attention sparsity, and token routing further improved runtime efficiency.
Why Gemma 3n Matters
Gemma 3n signals a shift in how foundational models are built and deployed. Instead of pushing toward ever-larger model sizes, it focuses on:
- Architecture-driven efficiency
- Multimodal comprehension
- Deployment portability
It aligns with Google’s broader vision for on-device AI: smarter, faster, more private, and universally accessible. For developers and enterprises, this means AI that runs on commodity hardware while delivering the sophistication of cloud-scale models.
Conclusion
With the launch of Gemma 3n, Google is not just releasing another foundation model; it is redefining the infrastructure of intelligent computing at the edge. The availability of E2B and E4B variants provides flexibility for both lightweight mobile applications and high-performance edge AI tasks. As multimodal interfaces become the norm, Gemma 3n stands out as a practical and powerful foundation model optimized for real-world usage.
Check out the Technical details, Models on Hugging Face and Try it on Google Studio. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

