










Google DeepMind Unveils MusicRL: A Pretrained Autoregressive MusicLM Model of Discrete Audio Tokens Finetuned with Reinforcement Learning to Maximise Sequence-Level Rewards


In the fascinating world of artificial intelligence and music, a team at Google DeepMind has made a groundbreaking stride. Their creation, MusicRL, is a beacon in the journey of music generation, leveraging the nuances of human feedback to shape the future of how machines understand and create music. This innovation stems from a simple yet profound realization: music, at its core, is a deeply personal and subjective experience. Traditional models, while technically proficient, often need to catch up on capturing the essence that makes music resonate on a personal level. MusicRL challenges this status quo by generating music and sculpting it according to the listener’s preferences.
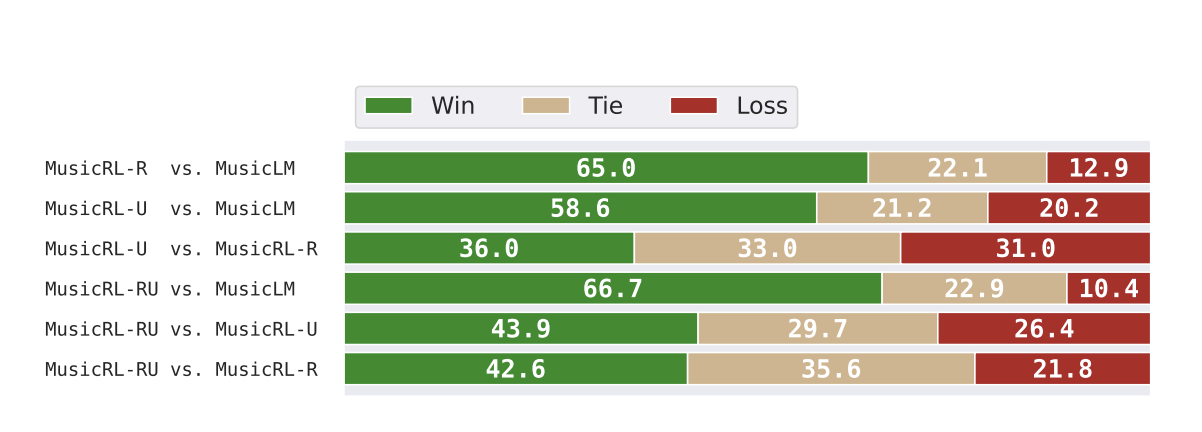
The brilliance of MusicRL lies in its methodology, a sophisticated dance between technology and human emotion. At its foundation is MusicLM, an autoregressive model that serves as the canvas for MusicRL’s creativity. The model then undergoes a process akin to learning from the collective wisdom of its audience, employing reinforcement learning to refine its outputs. This isn’t just algorithmic training; it’s a dialogue between creator and consumer, where each note and harmony is shaped by human touch. The system was exposed to a dataset of 300,000 pairwise preferences, a testament to its commitment to understanding the vast landscape of human musical taste.
The results of this endeavor are nothing short of remarkable. MusicRL doesn’t just perform; it enchants, offering a listening experience that users prefer over the baseline models in extensive evaluations. The numbers speak volumes, with MusicRL’s versions consistently outshining their predecessors in head-to-head comparisons. This isn’t merely a win in technical excellence but a victory in capturing the elusive spark that ignites human emotion through music. The dual versions, MusicRL-R and MusicRL-U, each fine-tuned with different facets of human feedback, showcase the model’s versatility in adapting to and reflecting the diversity of human preferences.
What sets MusicRL apart is its technical prowess and its philosophical underpinning—the recognition of music as an expression of the human experience. This approach has opened new doors in AI-generated music beyond replicating sound to creating emotionally resonant and personally tailored musical experiences. The implications are vast, from personalized music creation to new forms of interactive musical experiences, heralding a future where AI and human creativity harmonize in unprecedented ways.
MusicRL is more than a technological achievement; it’s a step towards a new understanding of how we interact with and appreciate music. It challenges us to rethink the role of AI in creative processes, inviting a future where technology not only replicates but enriches the human experience. As we stand on the brink of this new era, MusicRL serves as a beacon, illuminating the path toward a world where music is not just heard but felt, deeply and personally, across the spectrum of human emotion.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
