










Improving Robustness Against Bias in Social Science Machine Learning: The Promise of Instruction-Based Models

Language models (LMs) have gained significant prominence in computational text analysis, offering enhanced accuracy and versatility. However, a critical challenge persists: ensuring the validity of measurements derived from these models. Researchers face the risk of misinterpreting results, potentially measuring unintended factors such as incumbency instead of ideology, or party names rather than populism. This discrepancy between intended and actual measurements can lead to substantially flawed conclusions, undermining the credibility of research outcomes.
The fundamental question of measurement validity looms large in the field of computational social science. Despite the increasing sophistication of language models, concerns about the gap between the ambitions of these tools and the validity of their outputs remain. This issue has been a longstanding focus of computational social scientists, who have consistently warned about the challenges associated with validity in text analysis methods. The need to address this gap has become increasingly urgent as language models continue to evolve and expand their applications across various domains of research.
This study by researchers from Communication Science, Vrije Universiteit Amsterdam and Department of Politics, IR and Philosophy, Royal Holloway University of London addresses the critical issue of measurement validity in supervised machine learning for social science tasks, particularly focusing on how biases in fine-tuning data impact validity. The researchers aim to bridge the gap in social science literature by empirically investigating three key research questions: the extent of bias impact on validity, the robustness of different machine learning approaches against these biases, and the potential of meaningful instructions for language models to reduce bias and increase validity.
The study draws inspiration from the natural language processing (NLP) fairness literature, which suggests that language models like BERT or GPT may reproduce spurious patterns from their training data rather than truly understanding the concepts they are intended to measure. The researchers adopt a group-based definition of bias, considering a model biased if it performs unequally across social groups. This approach is particularly relevant for social science research, where complex concepts often need to be measured across diverse social groups using real-world training data that is rarely perfectly representative.
To tackle these challenges, the paper proposes and investigates instruction-based models as a potential solution. These models receive explicit, verbalized instructions for their tasks in addition to fine-tuning data. The researchers theorize that this approach might help models learn tasks more robustly and reduce reliance on spurious group-specific language patterns from the fine-tuning data, thereby potentially improving measurement validity across different social groups.
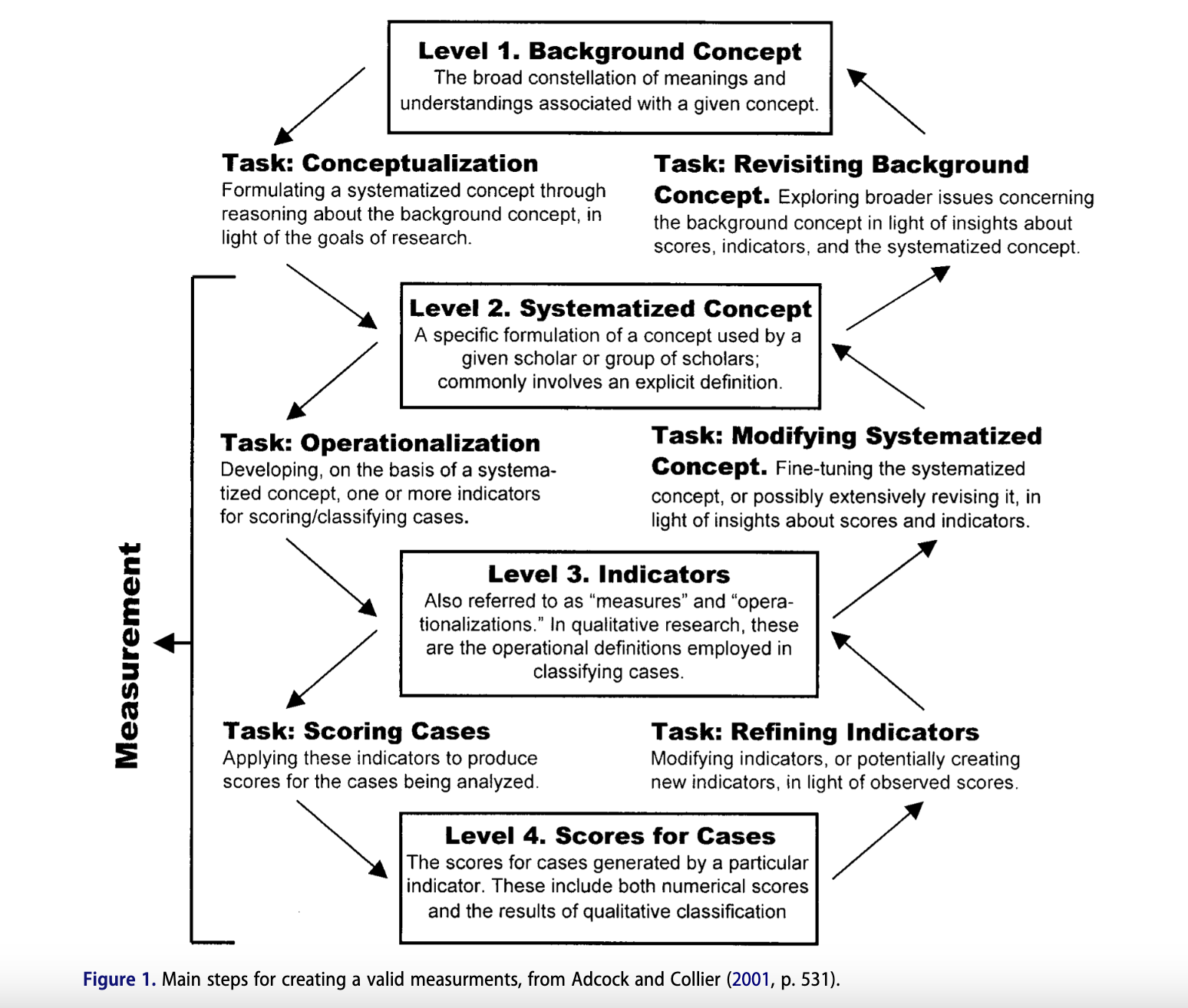
The proposed study addresses measurement validity in supervised machine learning for social science tasks, focusing on group-based biases in training data. Drawing from Adcock and Collier’s (2001) framework, the researchers emphasize robustness against group-specific patterns as crucial for validity. They highlight how standard machine learning models can become “stochastic parrots,” reproducing biases from training data without truly understanding concepts. To mitigate this, the study proposes investigating instruction-based models that receive explicit, verbalized task instructions alongside fine-tuning data. This approach aims to create a stronger link between the scoring process and the systematized concept, potentially reducing measurement error and enhancing validity across diverse social groups.
The proposed study investigates the robustness of different supervised machine learning approaches against biases in fine-tuning data, focusing on three main classifier types: logistic regression, BERT-base (DeBERTa-v3-base), and BERT-NLI (instruction-based). The study design involves training these models on four datasets across nine types of groups, comparing performance under biased and random training conditions.
Key aspects of the methodology include:
1. Training models on texts sampled from only one group (biased condition) and randomly across all groups (random condition).
2. Testing on a representative held-out test set to measure the “bias penalty” – the performance difference between biased and random conditions.
3. Using 500 texts with balanced classes for training to eliminate class imbalance as an intervening variable.
4. Conducting multiple training runs across six random seeds to reduce the influence of randomness.
5. Employing binomial mixed-effects regression to analyze classification errors, considering classifier type and whether test texts come from the same group as training data.
6. Testing the impact of meaningful instructions by comparing BERT-NLI performance with both meaningful and meaningless instructions.
This comprehensive approach aims to provide insights into the extent of bias impact on validity, the robustness of different classifiers against biases, and the potential of meaningful instructions to reduce bias and increase validity in supervised machine learning for social science tasks.

This study investigates the impact of group-based biases in machine learning training data on measurement validity across various classifiers, datasets, and social groups. The researchers found that all classifier types learn group-based biases, but the effects are generally small. Logistic regression showed the largest performance drop (2.3% F1 macro) when trained on biased data, followed by BERT-base (1.7% drop), while BERT-NLI demonstrated the smallest decrease (0.4% drop). Error probabilities on unseen groups increased for all models, with BERT-NLI showing the least increase. The study attributes BERT-NLI’s robustness to its algorithmic structure and ability to incorporate task definitions as plain text instructions, reducing dependence on group-specific language patterns. These findings suggest that instruction-based models like BERT-NLI may offer improved measurement validity in supervised machine learning for social science tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

