










Linguistics-aware In-context Learning with Data Augmentation (LaiDA): An AI Framework for Enhanced Metaphor Components Identification in NLP Tasks

Metaphor Components Identification (MCI) is an essential aspect of natural language processing (NLP) that involves identifying and interpreting metaphorical elements such as tenor, vehicle, and ground. These components are critical for understanding metaphors, which are prevalent in daily communication, literature, and scientific discourse. Accurately processing metaphors is vital for various NLP applications, including sentiment analysis, information retrieval, and machine translation. Given the intricate nature of metaphors and their reliance on context and background knowledge, MCI presents a unique challenge in computational linguistics.
The primary issue in MCI lies in the complexity and diversity of metaphors. Traditional approaches to identifying these metaphorical elements often fall short due to their reliance on manually crafted rules and dictionaries, which are limited in scope and adaptability. These methods struggle with the nuances of metaphors, particularly when understanding the context in which they are used. As metaphors often require a deep understanding of both language and cultural context, traditional computational methods have faced significant challenges in achieving accurate identification and interpretation.
In recent years, deep learning has offered new possibilities for MCI. Neural network models based on word embeddings and sequence models have shown promise in enhancing metaphor recognition capabilities. However, these models still encounter difficulties in contextual understanding and generalization. While they have improved upon previous rule-based approaches, their ability to handle the variability and complexity inherent in metaphors remains limited. As such, there is a need for more advanced methods that can effectively address these challenges and improve the accuracy of MCI.
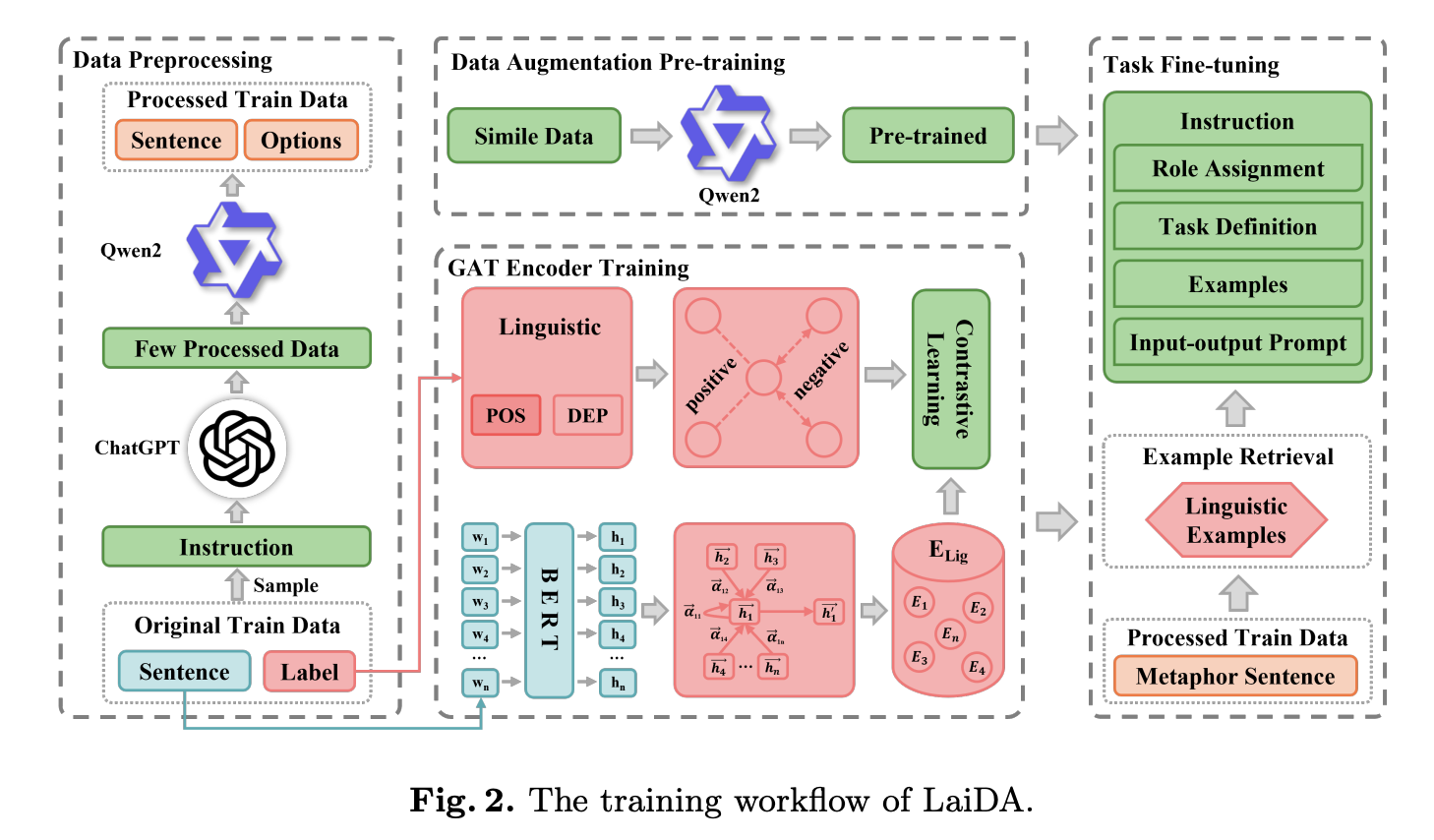
Researchers from Zhengzhou University introduced a new framework known as Linguistics-aware In-context Learning with Data Augmentation (LaiDA). This framework leverages the power of large language models (LLMs) like ChatGPT to improve the accuracy and efficiency of MCI. LaiDA integrates in-context learning with data augmentation techniques to create a more robust and adaptable method for metaphor recognition. By incorporating linguistically similar examples during the fine-tuning process, LaiDA enhances the model’s ability to understand and process complex metaphors.
The framework begins by utilizing ChatGPT to construct a high-quality benchmark dataset for MCI tasks. This dataset is then used to fine-tune a smaller LLM, further employed to generate a larger dataset. LaiDA incorporates a simile dataset for pre-training, allowing the model to grasp fundamental metaphorical patterns before tackling the main dataset. A key component of LaiDA is its graph attention network (GAT) encoder, which generates linguistically rich feature representations. These representations enable the retrieval of similar examples from the training set, which are then integrated into the fine-tuning process. This approach enhances the model’s ability to recognize metaphors and improves its generalization capabilities across different types of metaphorical expressions.
The framework achieved a remarkable accuracy of 93.21% in the NLPCC2024 Shared Task 9, ranking second overall. LaiDA demonstrated particular strength in identifying metaphors’ tenor and vehicle components, with accuracies of 97.20% and 97.32%, respectively. However, the accuracy for determining the ground component was slightly lower at 94.14%, highlighting the increased difficulty in capturing this aspect of metaphors. The application of LaiDA also resulted in a 0.9% increase in accuracy when the data augmentation pre-training module was included and a 2.6% increase when in-context learning was utilized. These results underscore the significant impact of LaiDA’s innovative approach to MCI.

In conclusion, the research team from Zhengzhou University has made a significant contribution to the field of MCI with the introduction of LaiDA. By combining linguistics-aware in-context learning with data augmentation, LaiDA offers a powerful tool for improving the accuracy and efficiency of metaphor recognition in NLP tasks. The framework’s ability to integrate linguistically similar examples during fine-tuning and its use of advanced LLMs and a GAT encoder sets a new standard in the field. The success of LaiDA in the NLPCC2024 Shared Task 9 further validates its effectiveness, making it a valuable resource for folks working on metaphor identification and interpretation.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.

