










MagpieLM-4B-Chat-v0.1 and MagpieLM-8B-Chat-v0.1 Released: Groundbreaking Open-Source Small Language Models for AI Alignment and Research


The University of Washington and the Allen Institute for AI (Ai2) have recently made a significant contribution to the AI research community by releasing their cutting-edge language models: MagpieLM-4B-Chat-v0.1 and MagpieLM-8B-Chat-v0.1. Part of the larger MagpieLM project, these models are specifically designed to address the rising need for aligned language models that can perform advanced text generation tasks while adhering to human values and expectations. The models, freely available on Hugging Face, have generated excitement within the AI research community due to their performance and transparency.
The MagpieLM-Chat Models
The MagpieLM-Chat models, MagpieLM-4B-Chat-v0.1 and MagpieLM-8B-Chat-v0.1, are two new language models optimized for alignment. This means they are specifically trained to ensure their outputs align with human instructions, ethical standards, and behavioral expectations. The 8B version refers to an 8-billion parameter model, while the 4B version is a distilled variant, reduced in size but still highly efficient.
Both models were trained using synthetic data generated by a unique technique called Magpie. This method was developed specifically to enhance the alignment of large language models (LLMs). By leveraging synthetic data, the Magpie team was able to train these models to understand and respond to human instructions in a more aligned, predictable manner. These models are based on Meta’s LLaMA-3.1-8B, a state-of-the-art LLM, and the 4B version was distilled by NVIDIA, further optimizing it for performance without sacrificing quality.
Open-Source and Transparent Approach
One of the most notable aspects of the MagpieLM-Chat project is its commitment to openness and reproducibility. The team has made the models and all relevant training data, configurations, and logs available to the public. This includes two critical datasets: the Supervised Fine-Tuning (SFT) and the Direct Preference Optimization (DPO) data. By releasing these alongside the models, the research team has made it possible for anyone to reproduce their research’s training and alignment processes. This is a crucial step toward democratizing AI research and ensuring more people have access to the tools needed to build and evaluate aligned language models.
The availability of the SFT and DPO datasets enables researchers to refine their models’ alignment further or experiment with different training approaches. These datasets are essential for training LLMs to be aligned, focusing on how models can be fine-tuned based on human preferences and feedback to ensure that their responses are accurate, ethical, and contextually appropriate.
Competitive Performance and Benchmarking
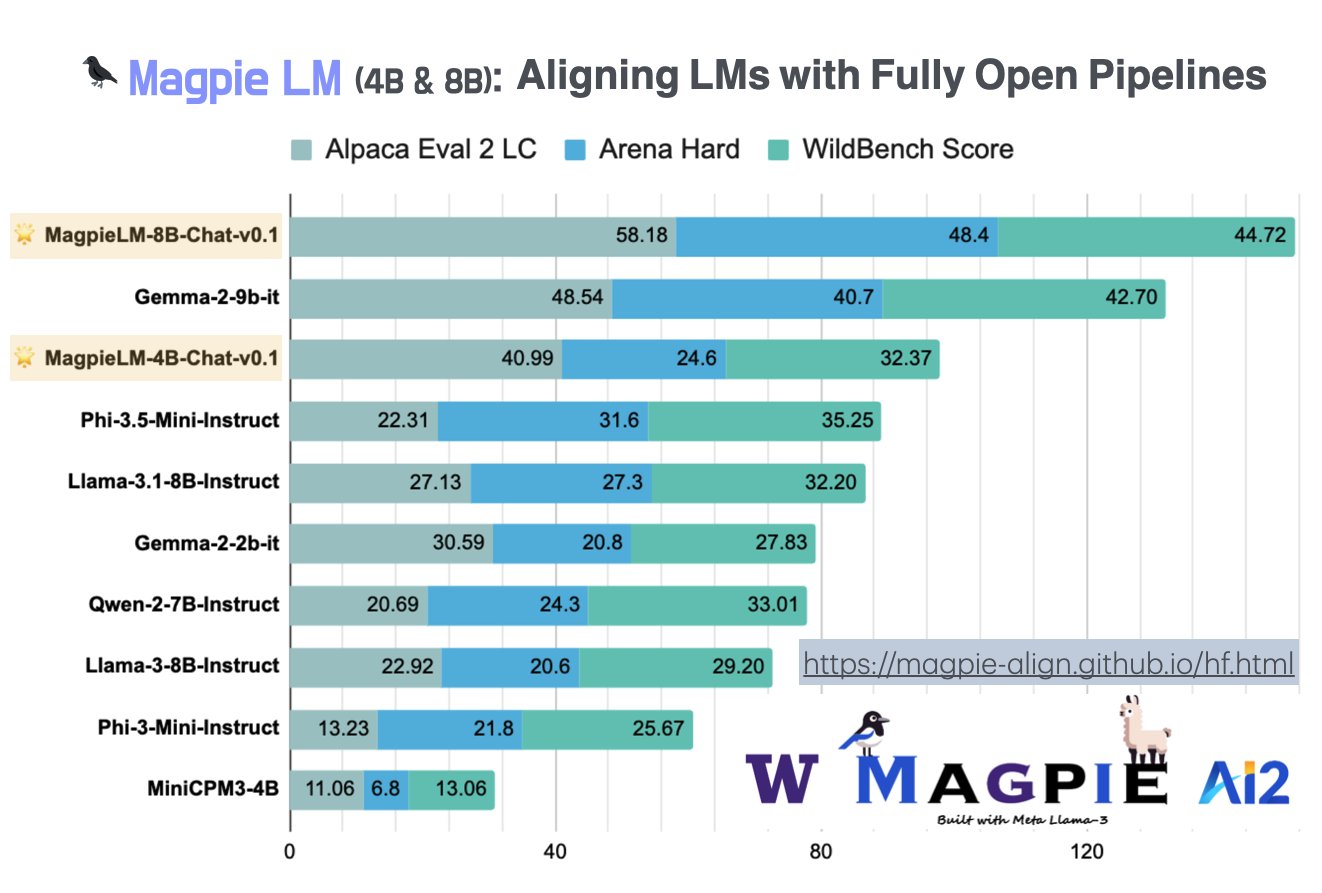
The release of MagpieLM-Chat is particularly significant because the models perform strongly on several key evaluation benchmarks. These benchmarks include WildBench, ArenaHard, and AlpacaEval, which assess how well language models handle complex, real-world tasks.
The MagpieLM-Chat models performed exceptionally well in evaluations, ranking as some of the best openly aligned LLMs on these benchmarks. WildBench tests a model’s general alignment capabilities across diverse tasks, ArenaHard focuses on the model’s ability to handle more challenging and nuanced instructions, and AlpacaEval assesses overall text generation quality. The fact that MagpieLM-Chat models excelled in these evaluations underscores the effectiveness of the Magpie alignment method and the rigorous post-training alignment process applied to these models.
Other Releases: SFT-Data and DPO-Data
In addition to the MagpieLM-Chat models, the team has released two major datasets: MagpieLM-SFT-Dat-v0.1 and MagpieLM-DPO-Data-v0.1. These datasets represent an enormous resource for AI researchers interested in alignment and post-training techniques.
The SFT-Data (Supervised Fine-Tuning Data) consists of approximately 550,000 data points that have been meticulously curated to enhance the supervised fine-tuning of language models. Supervised fine-tuning is essential in developing AI models, allowing them to learn from labeled examples and gradually improve their accuracy in following human instructions.
Meanwhile, the DPO-Data (Direct Preference Optimization Data) includes about 200,000 data points, allowing models to be trained based on preference signals. DPO is a crucial technique in reinforcement learning, enabling models to generate accurate responses and rank them according to human preferences, ensuring that the most aligned and contextually appropriate answers are prioritized. The release of these two datasets is particularly valuable for researchers looking to experiment with post-training alignment and reinforcement learning techniques.
Post-Training Alignment and Synthetic Data
At the core of this release, the Magpie method focuses on post-training alignment using synthetic data. This process takes a pretrained model, like LLaMA, and refines its behavior to ensure it is aligned with human goals. Post-training alignment is a critical part of modern AI development because it allows researchers to take powerful, general-purpose language models and fine-tune them to ensure they generate ethically sound and contextually appropriate outputs.
The synthetic data used in this process was generated to cover various scenarios, making the alignment process more robust. By exposing the models to this synthetic data, the researchers ensured that they could handle a variety of instructions and produce responses that adhere to human values, especially in sensitive or ambiguous situations.
The Road Ahead: Data-Model Compatibility
The release of the MagpieLM-Chat models and the accompanying datasets is just the beginning. The research team has hinted that future developments will focus on data-model compatibility, a critical area of study in AI research. This involves ensuring that the data used to train models is compatible with the specific characteristics of the model itself, leading to more efficient and effective training processes. The team plans to release additional insights and research in this area, which could further enhance the alignment capabilities of LLMs and contribute to the broader field of AI ethics.
Conclusion
The release of MagpieLM-Chat models, in both 4B and 8B versions, marks a significant step forward in the field of AI alignment. Backed by the University of Washington, Ai2, and NVIDIA, this project provides high-performance, openly available language models and offers the research community valuable datasets and tools to explore the complexities of AI alignment further. With strong results on prominent benchmarks and a commitment to transparency, the MagpieLM-Chat project is poised to impact the future of aligned AI research. The openness of the models and data sets a new standard for accessibility in AI, making cutting-edge alignment research available to a wider audience and encouraging innovation across the field.
Check out the Paper, 4B Model, 8B Model, SFT data, and DPO data. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
