










Meet VideoSwap: An Artificial Intelligence Framework that Customizes Video Subject Swapping with Interactive Semantic Point Correspondence

Recently, there have been significant advancements in video editing, with editing using Artificial Intelligence (AI) at its forefront. Numerous novel techniques have emerged, and among them, Diffusion-based video editing stands out as a particularly promising field. It leverages pre-trained text-to-image/video diffusion models for tasks like style change, background swapping, etc. However, The challenging part in video editing is transferring motion from source to edited video and, most importantly, ensuring temporal consistency in the entire process.
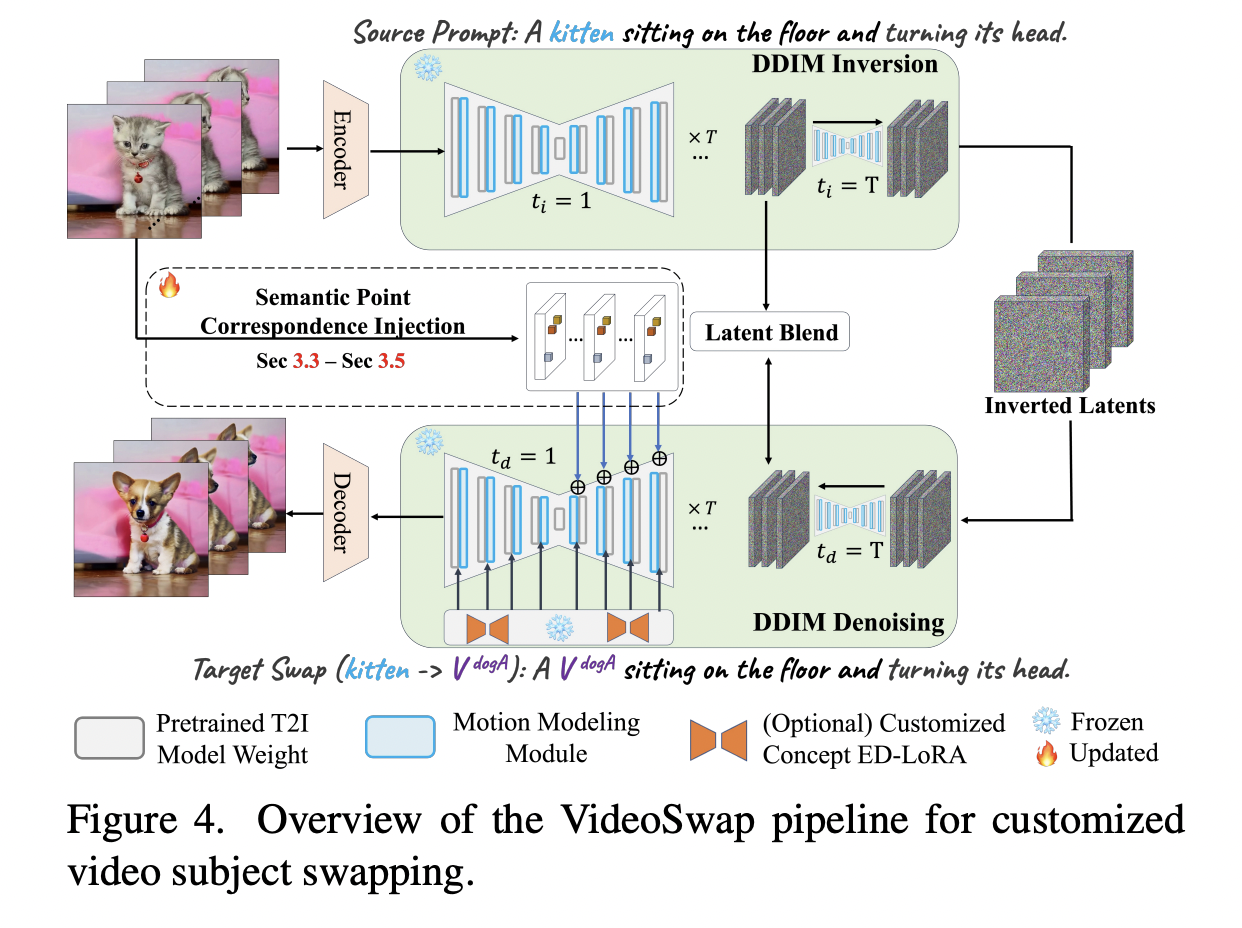
Most video editing tools focus on preserving the structure of the video by ensuring temporal consistency and motion alignment. This process becomes ineffective, though, when dealing with changing the shape in the video. To address this gap, the authors of this paper (researchers from Show Lab, National University of Singapore, and GenAI, Meta) have introduced VideoSwap, a framework that uses semantic point correspondences instead of dense ones to align the subject’s motion trajectory and alter its shape.
Using dense correspondences allows for better temporal consistency, but it limits the change in the shape of the subject in the edited video. Although using semantic point correspondences is a flexible method, it varies with different open-world settings, making it difficult to train a general condition model. The researchers tried to use only a limited number of source video frames to learn semantic point control. They found that the points optimized on source video frames can align the subject motion trajectory and change the subject’s shape as well. Moreover, the optimized semantic points could also be transferred across semantic and low-level changes. These observations make a point for using semantic point correspondence in video editing.
The researchers have designed the framework in the following ways. They have integrated the motion layer into the image diffusion model, which ensures temporal consistency. They have also identified semantic points in the source video and utilized them for transferring the motion trajectory. The method focuses only on high-level semantic alignment, which prevents it from learning excessive low-level details, thereby enhancing semantic point alignment. Moreover, VideoSwap also has user-point interactions, such as removing or dragging points for numerous semantic point correspondence.
The researchers implemented the framework using the Latent Diffusion Model and adopted the motion layer in AnimateDiff as the foundational model. They found that compared to previous video editing methods, VideoSwap achieved a significant shape change while simultaneously aligning the source motion trajectory along with preserving the target concept’s identity. The researchers also validated their results using human evaluators, and the results clearly show that VideoSwap outperformed the other compared methods on metrics like subject identity, motion alignment, and temporal consistency.
In conclusion, VideoSwap is a versatile framework that allows for video editing, even for those involving complex shapes. It limits human intervention during the process and uses semantic point correspondences for better video subject swapping. The method also allows for changing the shape while at the same time aligning the motion trajectory with the source object and outperforms previous methods on multiple metrics, demonstrating state-of-the-art results in customized video subject swapping.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
