










SynDL: A Synthetic Test Collection Utilizing Large Language Models to Revolutionize Large-Scale Information Retrieval Evaluation and Relevance Assessment


Information retrieval (IR) is a fundamental aspect of computer science, focusing on efficiently locating relevant information within large datasets. As data grows exponentially, the need for advanced retrieval systems becomes increasingly critical. These systems use sophisticated algorithms to match user queries with relevant documents or passages. Recent developments in machine learning, particularly in natural language processing (NLP), have significantly enhanced the capabilities of IR systems. By employing techniques such as dense passage retrieval and query expansion, researchers aim to improve the accuracy and relevance of search results. These advancements are pivotal in fields ranging from academic research to commercial search engines, where the ability to quickly & accurately retrieve information is essential.
A persistent challenge in information retrieval is the creation of large-scale test collections that can accurately model the complex relationships between queries and documents. Traditional test collections often rely on human assessors to judge the relevance of records, a process that is not only time-consuming but also costly. This reliance on human judgment limits the scale of test collections and hampers the developing and evaluation of more advanced retrieval systems. For instance, existing collections like MS MARCO include over 1 million questions, but for each query, only an average of 10 passages are deemed relevant, leaving approximately 8.8 million passages as non-relevant. This significant imbalance highlights the difficulty in capturing the full complexity of query-document relationships, particularly in large datasets.
Researchers have explored methods to enhance the effectiveness of IR systems. One approach uses large language models (LLMs), which have shown promise in generating relevance judgments that align closely with human assessments. The TREC Deep Learning Tracks, organized from 2019 to 2023, have been instrumental in advancing this research. These tracks have provided test collections that include queries with varying degrees of relevance labels. However, even these efforts have been constrained by the limited number of queries, only 82 in the 2023 track, used for evaluation. This limitation has sparked interest in developing new methods to scale the evaluation process while maintaining high accuracy and relevance.
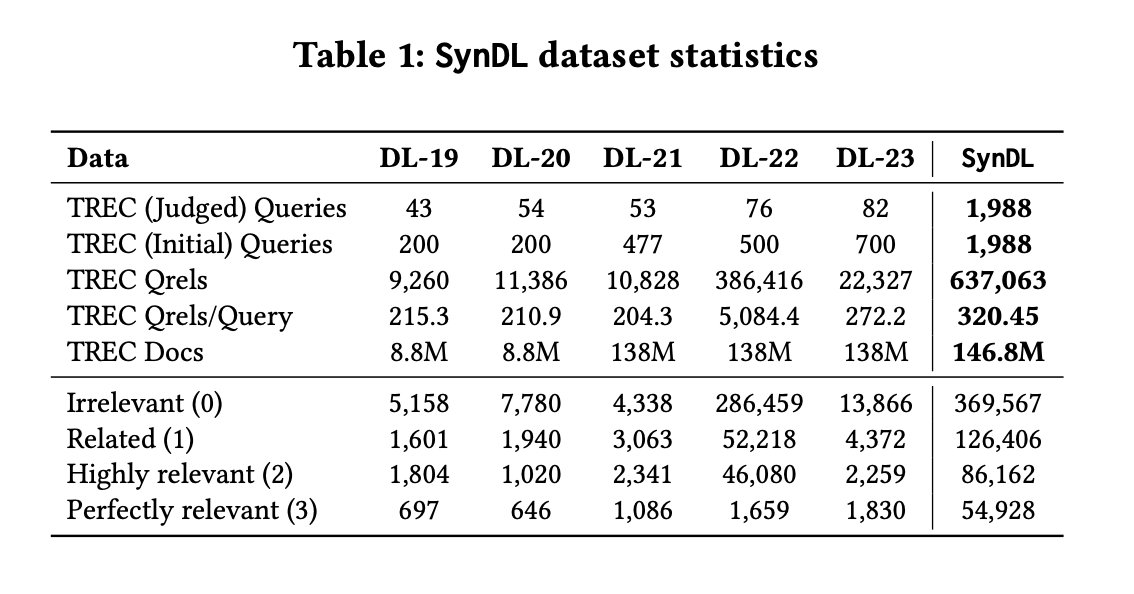
Researchers from University College London, University of Sheffield, Amazon, and Microsoft introduced a new test collection named SynDL. SynDL represents a significant advancement in the field of IR by leveraging LLMs to generate a large-scale synthetic dataset. This collection extends the existing TREC Deep Learning Tracks by incorporating over 1,900 test queries and generating 637,063 query-passage pairs for relevance assessment. The development process of SynDL involved aggregating initial queries from the five years of TREC Deep Learning Tracks, including 500 synthetic queries generated by GPT-4 and T5 models. These synthetic queries allow for a more extensive analysis of query-document relationships and provide a robust framework for evaluating the performance of retrieval systems.
The core innovation of SynDL lies in its use of LLMs to annotate query-passage pairs with detailed relevance labels. Unlike previous collections, SynDL offers a deep and wide relevance assessment by associating each query with an average of 320 passages. This approach increases the scale of the evaluation and provides a more nuanced understanding of the relevance of each passage to a given query. SynDL effectively bridges the gap between human and machine-generated relevance judgments by leveraging LLMs’ advanced natural language comprehension capabilities. The use of GPT-4 for annotation has been particularly noteworthy, as it enables high granularity in labeling passages as irrelevant, related, highly relevant, or perfectly relevant.
The evaluation of SynDL has demonstrated its effectiveness in providing reliable and consistent system rankings. In comparative studies, SynDL highly correlated with human judgments, with Kendall’s Tau coefficients of 0.8571 for NDCG@10 and 0.8286 for NDCG@100. Moreover, the top-performing systems from the TREC Deep Learning Tracks maintained their rankings when evaluated using SynDL, indicating the robustness of the synthetic dataset. The inclusion of synthetic queries also allowed researchers to analyze potential biases in LLM-generated text, particularly regarding the use of similar language models in both query generation and system evaluation. Despite these concerns, SynDL exhibited a balanced evaluation environment, where GPT-based systems did not receive undue advantages.
In conclusion, SynDL represents a major advancement in information retrieval by addressing the limitations of existing test collections. Through the innovative use of large language models, SynDL provides a large-scale, synthetic dataset that enhances the evaluation of retrieval systems. With its detailed relevance labels and extensive query coverage, SynDL offers a more comprehensive framework for assessing the performance of IR systems. The successful correlation with human judgments and the inclusion of synthetic queries make SynDL a valuable resource for future research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
