










This AI Paper by Alibaba Introduces Data-Juicer Sandbox: A Probe-Analyze-Refine Approach to Co-Developing Multi-Modal Data and Generative AI Models


Multi-modal generative models integrate various data types, such as text, images, and videos, expanding AI applications across different fields. However, optimizing these models presents complex challenges related to data processing and model training. The need for cohesive strategies to refine both data and models is crucial for achieving superior AI performance.
A major issue in multi-modal generative model development is the isolated progression of data-centric and model-centric approaches. Researchers often struggle to integrate data processing and model training, leading to inefficiencies and suboptimal results. This separation hampers the ability to enhance data and models simultaneously, which is essential for improving AI capabilities.
Current methods for developing multi-modal generative models typically focus either on refining algorithms and model architectures or enhancing data processing techniques. These methods operate independently, relying on heuristic approaches and human intuition. Consequently, they lack systematic guidance for collaborative optimization of data and models, resulting in fragmented and less effective development efforts.
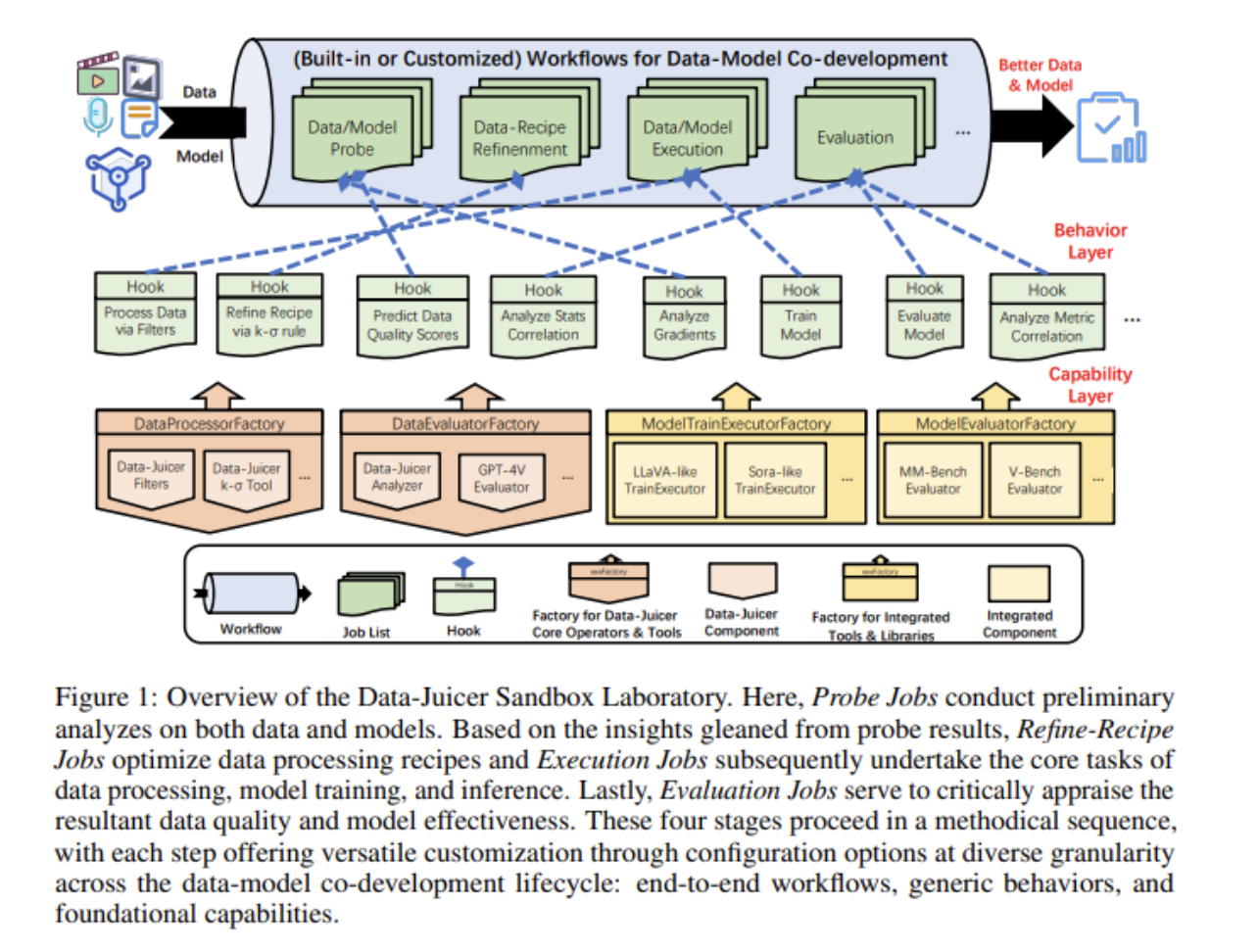
Researchers from Alibaba Group have introduced the Data-Juicer Sandbox, an open-source suite, to address these challenges. This sandbox facilitates the co-development of multi-modal data and generative models by integrating a variety of customizable components. It offers a flexible platform for systematic exploration and optimization, bridging the gap between data processing and model training. The suite is designed to streamline the development process and enhance the synergy between data and models.
The Data-Juicer Sandbox employs a “Probe-Analyze-Refine” workflow, allowing researchers to test and refine different data processing operators (OPs) and model configurations systematically. This method involves creating equal-size data pools, each processed uniquely by a single OP. Models are trained on these data pools, enabling in-depth analysis of OP effectiveness and its correlation with model performance across various quantitative and qualitative indicators. This systematic approach improves both data quality and model performance, providing valuable insights into the complex interplay between data preprocessing and model behavior.
In their methodology, the researchers implemented a hierarchical data pyramid, categorizing data pools based on their ranked model metric scores. This stratification helps identify the most effective OPs, which are then combined into data recipes and scaled up. By maintaining consistent hyperparameters and using cost-effective strategies like downsizing data pools and limiting training iterations, the researchers ensured an efficient and resource-conscious development process. The sandbox’s compatibility with existing model-centric infrastructures makes it a versatile tool for AI development.
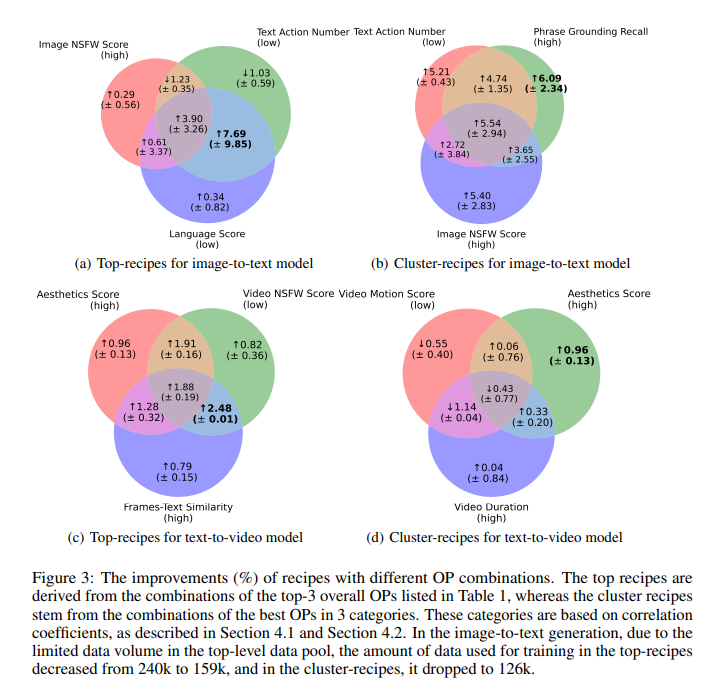
The Data-Juicer Sandbox achieved significant performance improvements in several tasks. For image-to-text generation, the average performance on TextVQA, MMBench, and MME increased by 7.13%. In text-to-video generation, using the EasyAnimate model, the sandbox achieved the top spot on the VBench leaderboard, outperforming strong competitors. The experiments also demonstrated a 59.9% increase in aesthetic scores and a 49.9% improvement in language scores when using high-quality data pools. These results highlight the sandbox’s effectiveness in optimizing multi-modal generative models.
Moreover, the sandbox facilitated practical applications in two distinct scenarios: image-to-text generation and text-to-video generation. In the image-to-text task, using the Mini-Gemini model, the sandbox achieved top-tier performance in understanding image content. For the text-to-video task, the EasyAnimate model demonstrated the sandbox’s capability to generate high-quality videos from textual descriptions. These applications exemplified the sandbox’s versatility and effectiveness in enhancing multi-modal data-model co-development.
In conclusion, the Data-Juicer Sandbox addresses the critical problem of integrating data processing and model training in multi-modal generative models. By providing a systematic and flexible platform for co-development, it enables researchers to achieve significant improvements in AI performance. This innovative approach represents a major advancement in the field of AI, offering a comprehensive solution to the challenges of optimizing multi-modal generative models.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.

