










This AI Paper from China Introduces BGE-M3: A New Member to BGE Model Series with Multi-Linguality (100+ languages)
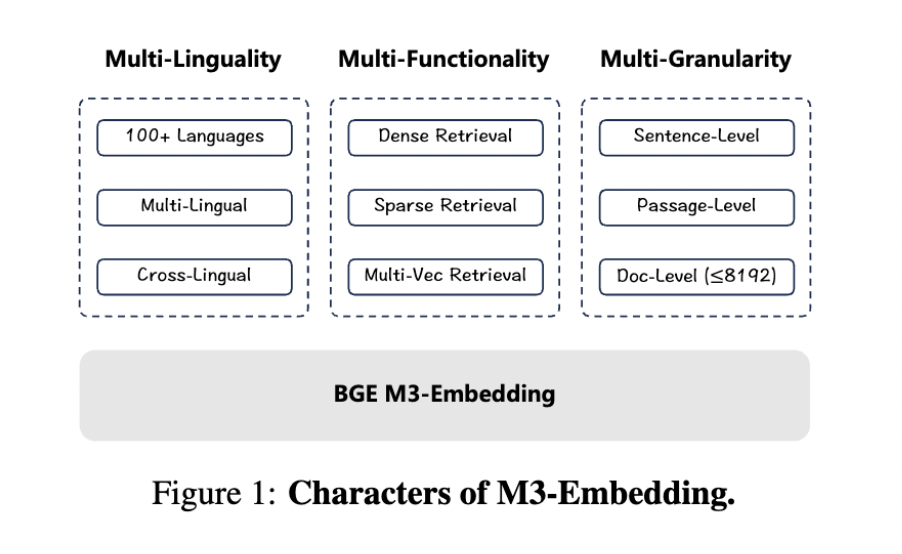


BAAI introduces BGE M3-Embedding with the help of researchers from the University of Science and Technology of China. The M3 refers to three novel properties of text embedding- Multi-Lingual, Multi-Functionality, and Multi-Granularity. It identifies the primary challenges in the existing embedding models, like being unable to support multiple languages, restrictions in retrieval functionalities, and difficulty handling varied input granularities.
Existing embedding models, such as Contriever, GTR, E5, and others, have been proven to bring notable progress in the field, but they lack language support, multiple retrieval functionality, or long input texts. These models are mainly trained only for English and support only one retrieval functionality. The proposed solution, BGE M3-Embedding, supports over 100 languages, accommodates diverse retrieval functionalities (dense, sparse, and multi-vector retrieval), and processes input data ranging from short sentences to lengthy document handling up to 8192 tokens.
M3-Embedding involves a novel self-knowledge distillation approach, optimizing batching strategies for large input lengths, for which researchers used large-scale, diverse multi-lingual datasets from various sources like Wikipedia and S2ORC. It facilitates three common retrieval functionalities: dense retrieval, lexical retrieval, and multi-vector retrieval. The distillation process involves combining relevance scores from various retrieval functionalities to create a teacher signal that enables the model to perform multiple retrieval tasks efficiently.
The model is evaluated for its performance with multilingual text(MLDR), varied sequence length, and narrative QA responses. The evaluation metric was nDCG@10(normalized discounted cumulative gain). The experiments demonstrated that the M3 embedding model outperformed existing models in more than 10 languages, giving at-par results in English. The model performance was similar to the other models with smaller input lengths but showcased improved results with longer texts.
In conclusion, M3 embedding is a significant advancement in text embedding models. It is a versatile solution that supports multiple languages, varied retrieval functionalities, and different input granularities. The proposed model addresses crucial limitations in existing methods, marking a substantial step forward in information retrieval. It outperforms baseline methods like BM25, mDPR, and E5, showcasing its effectiveness in addressing the identified challenges.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.