










This AI Paper from China Introduces DREditor: A Time-Efficient AI Approach for Building a Domain-Specific Dense Retrieval Model



Deploying dense retrieval models is crucial in industries like enterprise search (ES), where a single service supports multiple enterprises. In ES, such as the Cloud Customer Service (CCS), personalized search engines are generated from uploaded business documents to assist customer inquiries. The success of ES providers relies on delivering time-efficient searching customization to meet scalability requirements. Failure to do so may lead to delays, impacting enterprise needs and causing a poor customer experience with potential business loss.
The problem with the existing models, like implicit via long-time fine-tuning of retrieval models, is that they are time-consuming and may not provide optimal results. Longer training time is an issue as it consumes significant computational resources, leading to increased costs for infrastructure and energy consumption. Secondly, prolonged training times hinder the rapid development and experimentation cycles crucial for refining models and adapting them to changing requirements. Hence, the problem requires a new solution.
The researchers from the College of Computer Science, Sichuan University and Engineering Research Center of Machine Learning and Industry Intelligence, Ministry of Education Chengdu, China, have introduced DREditor, a time-efficient method for adapting off-the-shelf dense retrieval models to specific domains. Utilizing efficient linear mapping, DREditor calibrates output embeddings by solving a least squares problem with a specially constructed edit operator. In contrast to lengthy fine-tuning processes, experimental results demonstrate that DREditor achieves 100–300 times faster time efficiency across various datasets, sources, models, and devices while maintaining or surpassing retrieval performance.
DREditor employs adapter fine-tuning and introduces a time-efficient approach by directly calibrating output embeddings using a linear mapping technique. It solves a specially constructed least squares problem to obtain an edit operator. The method significantly reduces customization time compared to traditional approaches, enhancing the generalization capacity of DR models across specific domains. The post-processing step of DREditor’s matching rule editing involves a computation-efficient linear transformation powered by the derived edit operator.
DREditor exhibits substantial advantages in time efficiency, achieving a 100-300 times reduction in customization time compared to traditional fine-tuning methods while maintaining or surpassing retrieval performance. The approach outperforms implicit rule modification techniques. Experimental results highlight DREditor’s effectiveness across diverse datasets, sources, retrieval models, and computing devices. The research emphasizes the method’s contribution to filling a technical gap in embedding calibration, enabling cost-effective and efficient development of domain-specific dense retrieval models.
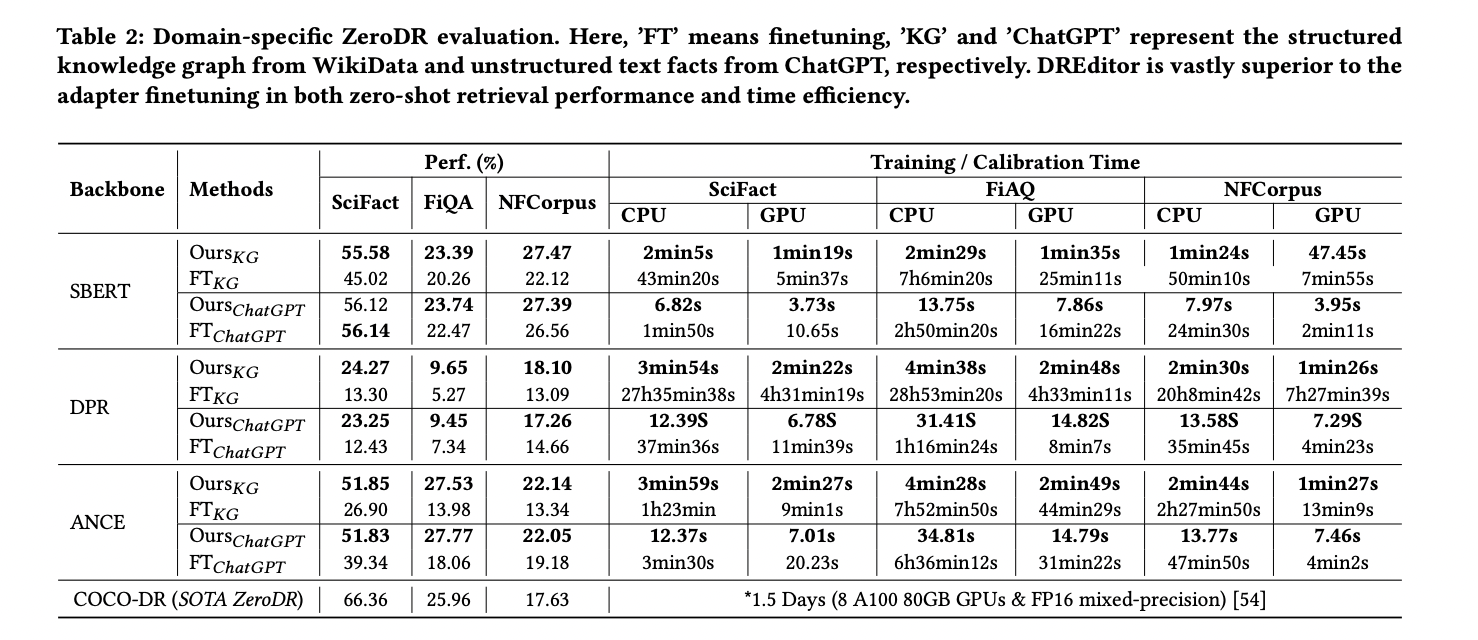
To sum up, The researchers from the College of Computer Science, Sichuan University, and the Engineering Research Center of Machine Learning and Industry Intelligence, Ministry of Education Chengdu, China, have introduced the DREditor, a domain-specific dense retrieval model time-efficiently. This approach facilitates timely customization for enterprise search providers, ensuring scalability and meeting time-sensitive demands. A noteworthy contribution is the integration of emerging studies on embedding calibration into retrieval tasks. The method extends applicability to zero-shot domain-specific scenarios, showcasing its potential for cost-effective and efficient development of domain-specific DR models.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
