










This AI Research Introduces Fast and Expressive LLM Inference with RadixAttention and SGLang


Advanced prompting mechanisms, control flow, contact with external environments, many chained generation calls, and complex activities are expanding the utilization of Large Language Models (LLMs). On the other hand, effective methods for developing and running such programs are severely lacking. LMSYS ORG presents SGLang, a Structured Generation Language for LLMs that collaborates on the architecture of both the backend runtime system and the frontend languages. SGLang improves interactions with LLMs, making them faster and more controllable.
Backend: Automatic KV Cache Reuse with RadixAttention
To take advantage of these reuse opportunities systematically, the team provides RadixAttention, a new automatic KV cache reuse method while running. The KV cache is not removed from the radix tree when a generation request is completed; it is kept for both the generation results and the prompts. This data structure makes efficient search, insertion, and eviction of prefixes possible. To improve the cache hit rate, the researchers employ a cache-aware scheduling policy in conjunction with a Least Recently Used (LRU) eviction policy. It can be eagerly executed using an interpreter or traced as a dataflow graph and run with a graph executor. In the second scenario, compiler optimizations like code relocation, instruction selection, and auto-tuning become possible.
Frontend: Easy LLM Programming with SGLang
The team also presents SGLang, an embedded domain-specific language in Python, on the front end. Complex methods of prompting, control flow, multi-modality, decoding limitations, and external interaction can be simply articulated using it. Users can run an SGLang function through local models, OpenAI, Anthropic, and Gemini.
As mentioned by the team, much of SGLang’s syntax takes cues from Guidance. Users also deal with batching and intra-program parallelism in addition to introducing new primitives. With all these new features, SGLang is much more powerful than before. Improve the cache hit rate with an eviction policy and a scheduling approach that considers cache awareness.
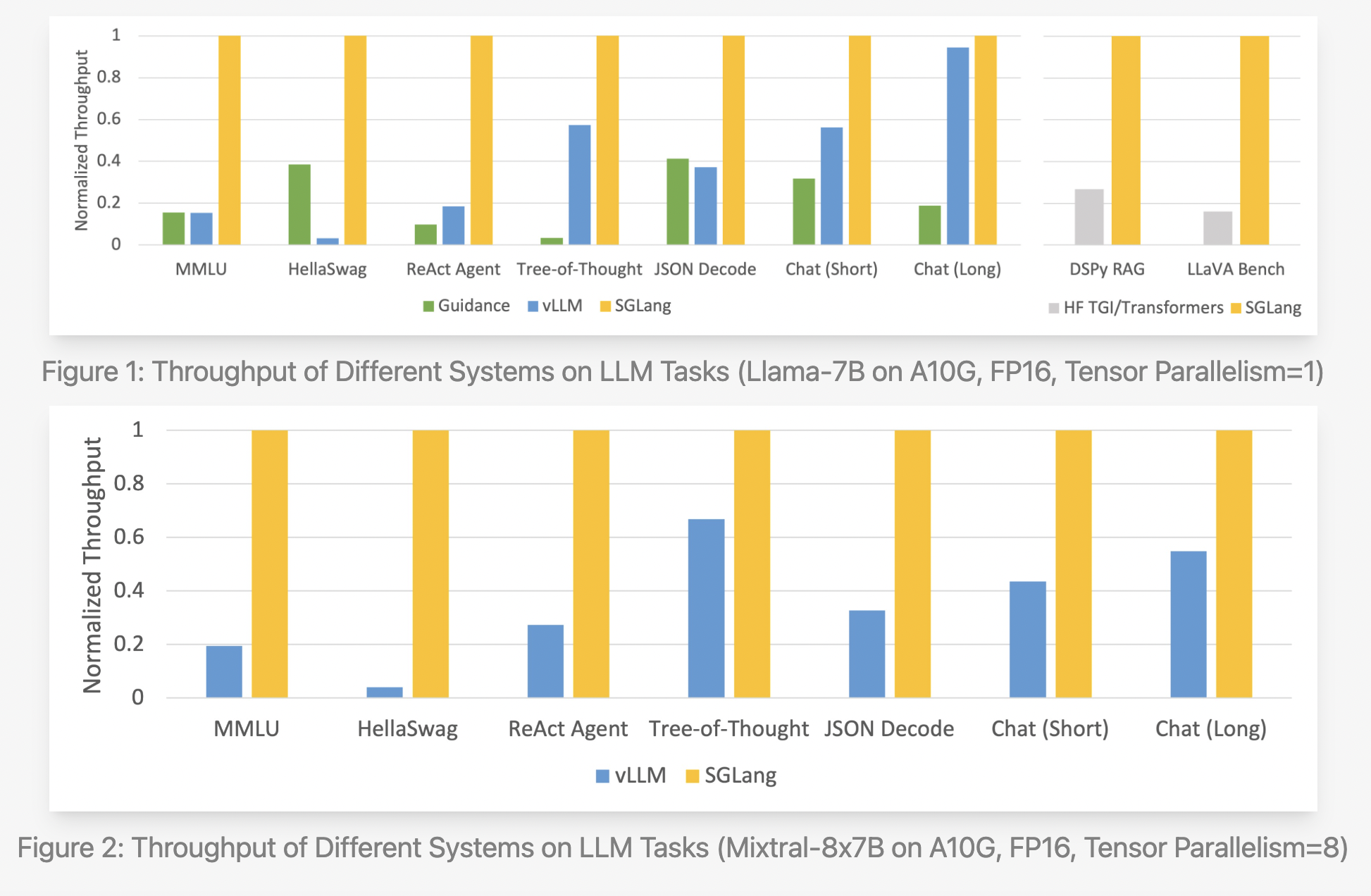
The researchers recorded the throughput their system attained when testing it on the following typical LLM workloads:
- MMLU: A multi-tasking, 5-shot, multiple-choice test.
- HellaSwag: An assessment tool for 20-shot, multiple-choice phrase completion.
- An agent job based on prompt traces taken from the original ReAct paper is ReAct Agent.
- Tree-of-Thought: A GSM-8K problem-solving prompt based on bespoke tree searches.
- A JSON decoder can parse a Wikipedia article and return its data in a JSON format.
- The chat (short) benchmark is a synthetic chat in which each conversation consists of four turns with brief LLM outputs.
- This synthetic chat benchmark uses long LLM outputs and four turns per conversation.
- DSPy RAG: A pipeline in the DSPy tutorial that uses retrieval to augment generation.
- The LLaVA-in-the-wild benchmark is used to run the vision language model LLaVA v1.5.
Using the Llama-7B and Mixtral-8x7B models on NVIDIA A10G GPUs, the team applied SGLang to typical LLM workloads such as agent, reasoning, extraction, chat, and few-shot learning tasks. The researchers used Hugging Face TGI v1.3.0, advice v0.1.8, and vllm v0.2.5 as a starting point. SGLang outperforms current systems, specifically Guid, by a factor of up to five in terms of throughput. It also performed quite well in latency tests, especially those involving the initial token, where a prefix cache hit is very useful. Current systems do a terrible job of handling sophisticated LLM programs, but while developing the SGLang runtime, it was observed that a critical optimization opportunity: KV cache reuse. By reusing the KV cache, many prompts that share the same prefix can use the intermediate KV cache, which saves both memory and computation. Many other KV cache reuse methods, including ance and vLLM, can be found in complicated programs that use many LLM calls. The automatic KV cache reuse with RadixAttention, the interpreter’s ability to provide intra-program parallelism, and the fact that the frontend and backend systems were co-designed all contribute to these benefits.
Check out the Code and Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.

