












TII Abu-Dhabi Released Falcon H1R-7B: A New Reasoning Model Outperforming Others in Math and Coding with only 7B Params with 256k Context Window


Technology Innovation Institute (TII), Abu Dhabi, has released Falcon-H1R-7B, a 7B parameter reasoning specialized model that matches or exceeds many 14B to 47B reasoning models in math, code and general benchmarks, while staying compact and efficient. It builds on Falcon H1 7B Base and is available on Hugging Face under the Falcon-H1R collection.
Falcon-H1R-7B is interesting because it combines 3 design choices in 1 system, a hybrid Transformer along with Mamba2 backbone, a very long context that reaches 256k tokens in standard vLLM deployments, and a training recipe that mixes supervised long form reasoning with reinforcement learning using GRPO.
Hybrid Transformer plus Mamba2 architecture with long context
Falcon-H1R-7B is a causal decoder only model with a hybrid architecture that combines Transformer layers and Mamba2 state space components. The Transformer blocks provide standard attention based reasoning, while the Mamba2 blocks give linear time sequence modeling and better memory scaling as context length grows. This design targets the 3 axes of reasoning efficiency that the team describes, speed, token efficiency and accuracy.
The model runs with a default –max-model-len of 262144 when served through vLLM, which corresponds to a practical 256k token context window. This allows very long chain of thought traces, multi step tool use logs and large multi document prompts in a single pass. The hybrid backbone helps control memory use at these sequence lengths and improves throughput compared with a pure Transformer 7B baseline on the same hardware.
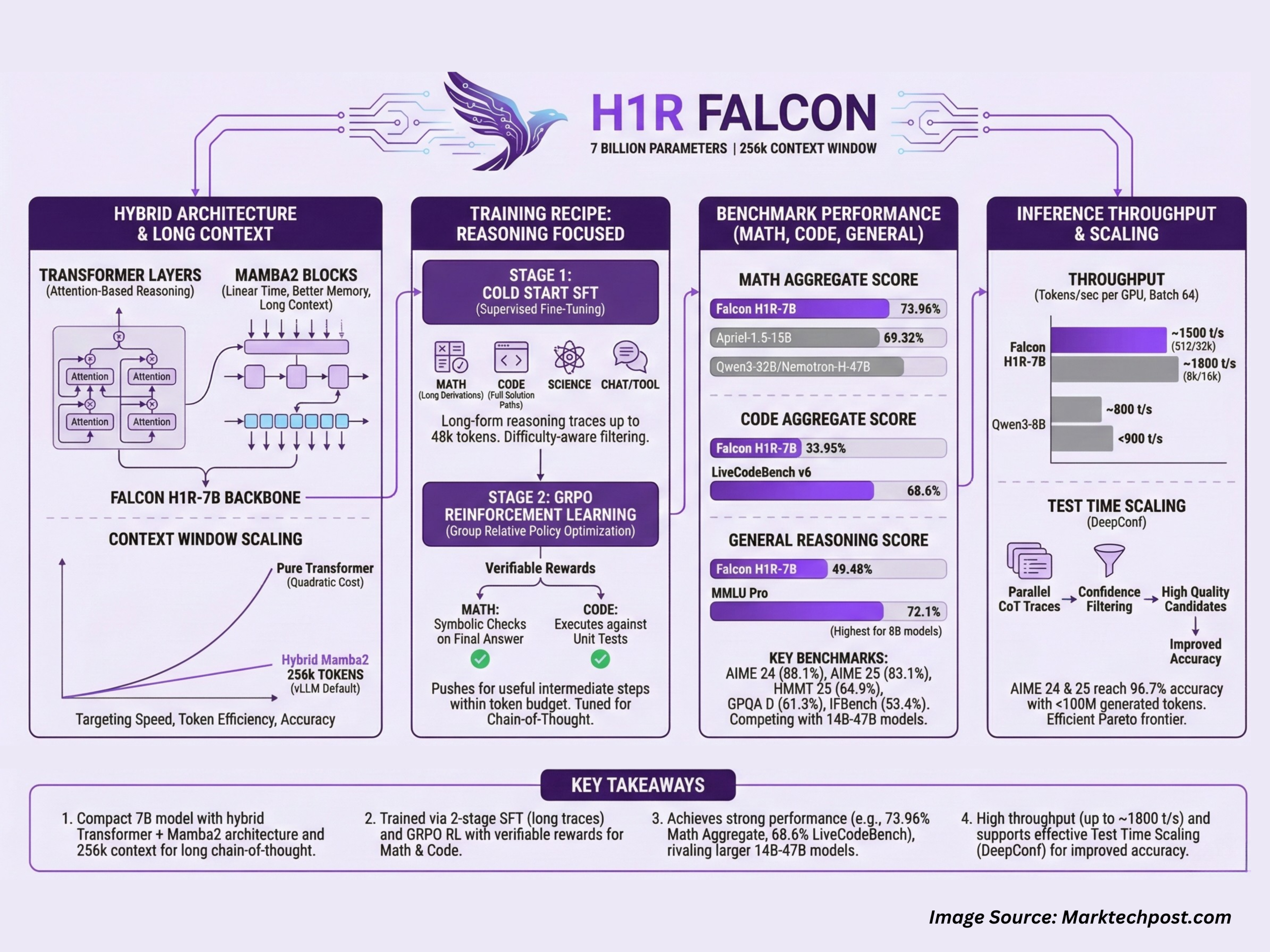
Training recipe for reasoning tasks
Falcon H1R 7B uses a 2 stage training pipeline:
In the first stage, the team runs cold start supervised fine tuning on top of Falcon-H1-7B Base. The SFT (supervised fine tuning) data mixes step by step long form reasoning traces in 3 main domains, mathematics, coding and science, plus non reasoning domains such as chat, tool calling and safety. Difficulty aware filtering upweights harder problems and downweights trivial ones. Targets can reach up to 48k tokens, so the model sees long derivations and full solution paths during training.
In the second stage, the SFT checkpoint is refined with GRPO, which is a group relative policy optimization method for reinforcement learning. Rewards are given when the generated reasoning chain is verifiably correct. For math problems, the system uses symbolic checks on the final answer. For code, it executes the generated program against unit tests. This RL stage pushes the model to keep useful intermediate steps while staying within a token budget.
The result is a 7B model that is tuned specifically for chain of thought reasoning, rather than general chat.
Benchmarks in math, coding and general reasoning
The Falcon-H1R-7B benchmark scores are grouped across math, code and agentic tasks, and general reasoning tasks.
In the math group, Falcon-H1R-7B reaches an aggregate score of 73.96%, ahead of Apriel-1.5-15B at 69.32% and larger models like Qwen3-32B and Nemotron-H-47B. On individual benchmarks:
- AIME 24, 88.1%, higher than Apriel-1.5-15B at 86.2%
- AIME 25, 83.1%, higher than Apriel-1.5-15B at 80%
- HMMT 25, 64.9%, above all listed baselines
- AMO Bench, 36.3%, compared with 23.3% for DeepSeek-R1-0528 Qwen3-8B
For code and agentic workloads, the model reaches 33.95% as a group score. On LiveCodeBench v6, Falcon-H1R-7B scores 68.6%, which is higher than Qwen3-32B and other baselines. It also scores 28.3% on the SciCode sub problem benchmark and 4.9% on Terminal Bench Hard, where it ranks second behind Apriel 1.5-15B but ahead of several 8B and 32B systems.

On general reasoning, Falcon-H1R-7B achieves 49.48% as a group score. It records 61.3% on GPQA D, close to other 8B models, 72.1% on MMLU Pro, which is higher than all other 8B models in the above table, 11.1% on HLE and 53.4% on IFBench, where it is second only to Apriel 1.5 15B.
The key takeaway is that a 7B model can sit in the same performance band as many 14B to 47B reasoning models, if the architecture and training pipeline are tuned for reasoning tasks.
Inference throughput and test time scaling
The team also benchmarked Falcon-H1R-7B on throughput and test time scaling under realistic batch settings.
For a 512 token input and 32k token output, Falcon-H1R-7B reaches about 1,000 tokens per second per GPU at batch size 32 and about 1,500 tokens per second per GPU at batch size 64, nearly double the throughput of Qwen3-8B in the same configuration. For an 8k input and 16k output, Falcon-H1R-7B reaches around 1,800 tokens per second per GPU, while Qwen3-8B stays below 900. The hybrid Transformer along with Mamba architecture is a key factor in this scaling behavior, because it reduces the quadratic cost of attention for long sequences.
Falcon-H1R-7B is also designed for test time scaling using Deep Think with confidence, known as DeepConf. The idea is to run many chains of thought in parallel, then use the model’s own next token confidence scores to filter noisy traces and keep only high quality candidates.
On AIME 24 and AIME 25, Falcon-H1R-7B reaches 96.7% accuracy with fewer than 100 million generated tokens, which puts it on a favorable Pareto frontier of accuracy versus token cost compared with other 8B, 14B and 32B reasoning models. On the parser verifiable subset of AMO Bench, it reaches 35.9% accuracy with 217 million tokens, again ahead of the comparison models at similar or larger scale.
Key Takeaways
- Falcon-H1R-7B is a 7B parameter reasoning model that uses a hybrid Transformer along with Mamba2 architecture and supports a 256k token context for long chain of thought prompts.
- The model is trained in 2 stages, supervised fine tuning on long reasoning traces in math, code and science up to 48k tokens, followed by GRPO based reinforcement learning with verifiable rewards for math and code.
- Falcon-H1R-7B achieves strong math performance, including about 88.1% on AIME 24, 83.1% on AIME 25 and a 73.96% aggregate math score, which is competitive with or better than larger 14B to 47B models.
- On coding and agentic tasks, Falcon-H1R-7B obtains 33.95% as a group score and 68.6% on LiveCodeBench v6, and it is also competitive on general reasoning benchmarks such as MMLU Pro and GPQA D.
- The hybrid design improves throughput, reaching around 1,000 to 1,800 tokens per second per GPU in the reported settings, and the model supports test time scaling through Deep Think with confidence to improve accuracy using multiple reasoning samples under a controlled token budget.
Check out the Technical details and MODEL WEIGHTS here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Check out our latest release of ai2025.dev, a 2025-focused analytics platform that turns model launches, benchmarks, and ecosystem activity into a structured dataset you can filter, compare, and export
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
The post TII Abu-Dhabi Released Falcon H1R-7B: A New Reasoning Model Outperforming Others in Math and Coding with only 7B Params with 256k Context Window appeared first on Tokention.