










UC Berkeley Researchers Introduce SERL: A Software Suite for Sample-Efficient Robotic Reinforcement Learning



In recent years, researchers in the field of robotic reinforcement learning (RL) have achieved significant progress, developing methods capable of handling complex image observations, training in real-world scenarios, and incorporating auxiliary data, such as demonstrations and prior experience. Despite these advancements, practitioners acknowledge the inherent difficulty in effectively utilizing robotic RL, emphasizing that the specific implementation details of these algorithms are often just as crucial, if not more so, for performance as the choice of the algorithm itself.
The above image is depiction of various tasks solved using SERL in the real world. These include PCB board insertion (left), cable routing (middle), and object relocation (right). SERL provides an out-of-the-box package for real-world reinforcement learning, with support for sample-efficient learning, learned rewards, and automation of resets.
Researchers have highlighted the significant challenge posed by the comparative inaccessibility of robotic reinforcement learning (RL) methods, hindering their widespread adoption and further development. In response to this issue, a meticulously crafted library has been created. This library incorporates a sample-efficient off-policy deep RL method and tools for reward computation and environment resetting. Additionally, it includes a high-quality controller tailored for a widely adopted robot, coupled with a diverse set of challenging example tasks. This resource is introduced to the community as a concerted effort to address accessibility concerns, offering a transparent view of its design decisions and showcasing compelling experimental results.
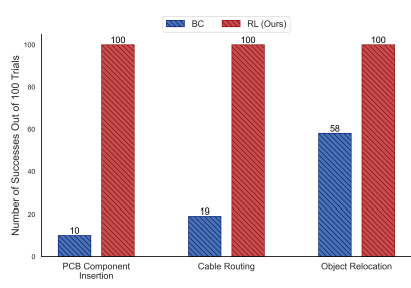
When evaluated for 100 trials per task, learned RL policies outperformed BC policies by a large margin, by 1.7x for Object Relocation, by 5x for Cable Routing, and by 10x for PCB Insertion!
The implementation demonstrates the capability to achieve highly efficient learning and obtain policies for tasks such as PCB board assembly, cable routing, and object relocation within an average training time of 25 to 50 minutes per policy. These results represent an improvement over state-of-the-art outcomes reported for similar tasks in the literature.
Notably, the policies derived from this implementation exhibit perfect or near-perfect success rates, exceptional robustness even under perturbations, and showcase emergent recovery and correction behaviors. Researchers hope that these promising outcomes, coupled with the release of a high-quality open-source implementation, will serve as a valuable tool for the robotics community, fostering further advancements in robotic RL.
In summary, the carefully crafted library marks a pivotal step in making robotic reinforcement learning more accessible. With transparent design choices and compelling results, it not only enhances technical capabilities but also fosters collaboration and innovation. Here’s to breaking down barriers and propelling the exciting future of robotic RL! 🚀🤖✨
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
