










Google DeepMind Introduces Direct Reward Fine-Tuning (DRaFT): An Effective Artificial Intelligence Method for Fine-Tuning Diffusion Models to Maximize Differentiable Reward Functions


Diffusion models have revolutionized generative modeling across various data types. However, in practical applications like generating aesthetically pleasing images from text descriptions, fine-tuning is often needed. Text-to-image diffusion models employ techniques like classifier-free guidance and curated datasets such as LAION Aesthetics to improve alignment and image quality.
In their research, the authors present a straightforward and efficient method for gradient-based reward fine-tuning, which involves differentiating through the diffusion sampling process. They introduce the concept of Direct Reward Fine-Tuning (DRaFT), which essentially backpropagates through the entire sampling chain, typically represented as an unrolled computation graph with a length of 50 steps. To manage memory and computational costs effectively, they employ gradient checkpointing techniques and optimize LoRA weights instead of modifying the entire set of model parameters.
The above image demonstrates DRaFT using human preference reward models. Furthermore, the authors introduce enhancements to the DRaFT method to enhance its efficiency and performance. First, they propose DRaFT-K, a variant that limits backpropagation to only the last K steps of sampling when computing the gradient for fine-tuning. Empirical results demonstrate that this truncated gradient approach significantly outperforms full backpropagation with the same number of training steps, as full backpropagation can lead to issues with exploding gradients.
Additionally, the authors introduce DRaFT-LV, a variation of DRaFT-1 that computes lower-variance gradient estimates by averaging over multiple noise samples, further improving efficiency in their approach.
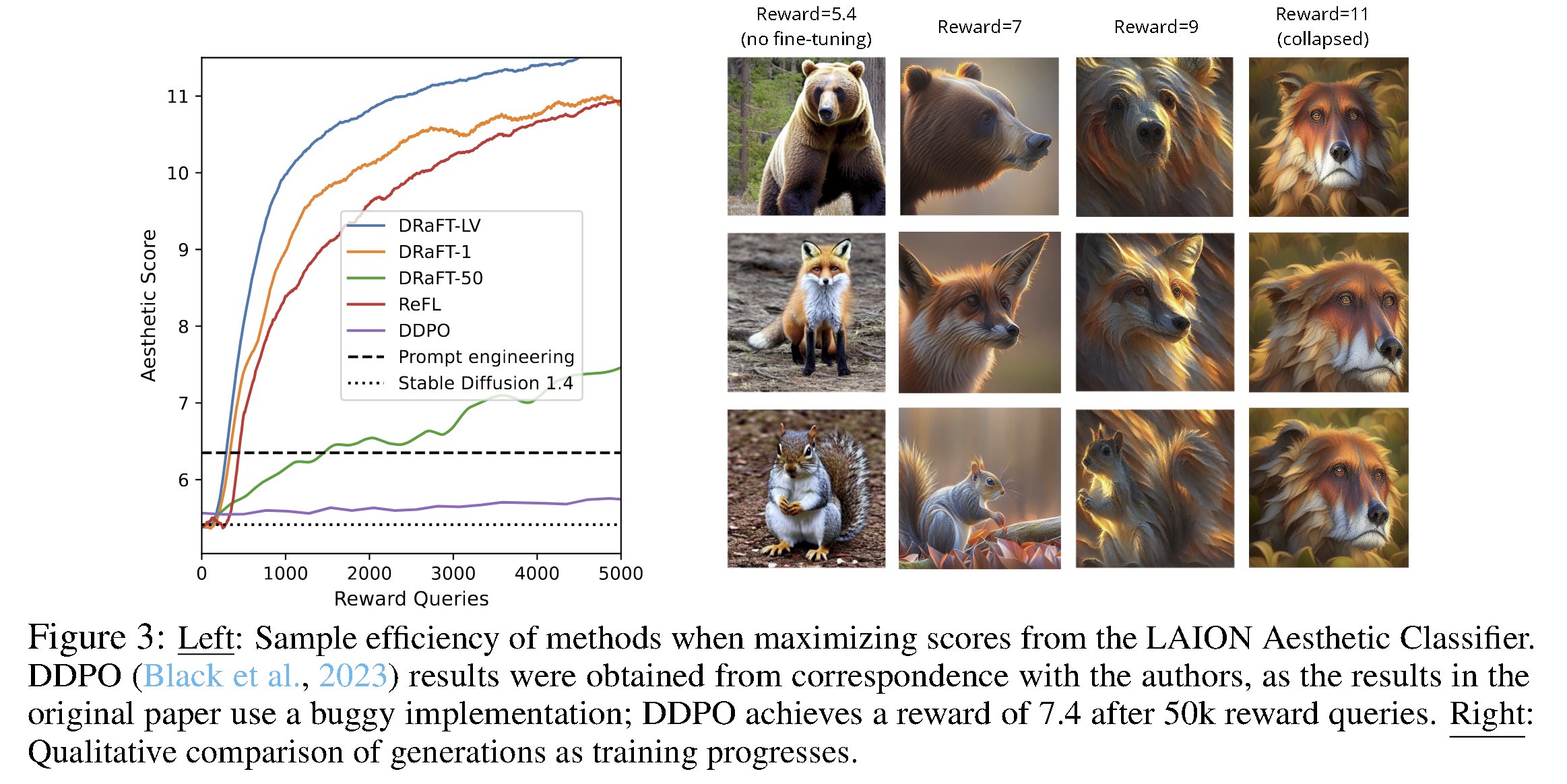
The authors of the study applied DRaFT to Stable Diffusion 1.4 and conducted evaluations using various reward functions and prompt sets. Their methods, which leverage gradients, demonstrated significant efficiency advantages compared to RL-based fine-tuning baselines. For instance, they achieved over a 200-fold speed improvement when maximizing scores from the LAION Aesthetics Classifier compared to RL algorithms.
DRaFT-LV, one of their proposed variations, exhibited exceptional efficiency, learning approximately twice as fast as ReFL, a prior gradient-based fine-tuning method. Furthermore, they demonstrated the versatility of DRaFT by combining or interpolating DRaFT models with pre-trained models, which can be achieved by adjusting LoRA weights through mixing or scaling.
In conclusion, directly fine-tuning diffusion models on differentiable rewards offers a promising avenue for improving generative modeling techniques, with implications for applications spanning images, text, and more. Its efficiency, versatility, and effectiveness make it a valuable addition to the toolkit of researchers and practitioners in the field of machine learning and generative modeling.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
