










Tsinghua University Researchers Introduce OpenChat: A Novel Artificial Intelligence AI Framework Enhancing Open-Source Language Models with Mixed-Quality Data


In the fast-evolving field of natural language processing, the capabilities of large language models have grown exponentially. Researchers and organizations worldwide are continually pushing the boundaries of these models to improve their performance in various natural language understanding and generation tasks. One critical aspect of advancing these models is the quality of the training data they rely on. In this article, we delve into a research paper that tackles the challenge of enhancing open-source language models using mixed-quality data. This research explores the proposed method, technology, and implications for natural language processing.
Mixed-quality data, including expert-generated and sub-optimal data, poses a significant challenge in training language models. Expert data generated by state-of-the-art models like GPT-4 is typically high quality and serves as a gold standard for training. On the other hand, sub-optimal data originating from older models like GPT-3.5 may exhibit lower quality and present challenges during training. This research under discussion acknowledges this mixed-quality data scenario and aims to improve the instruction-following abilities of open-source language models.
Before delving into the proposed method, let’s briefly touch upon current methods and tools used in language model training. One common approach to enhancing these models is Supervised Fine-Tuning (SFT). In SFT, models are trained on instruction-following tasks using high-quality expert-generated data, which guides generating correct responses. Additionally, Reinforcement Learning Fine-Tuning (RLFT) methods have gained popularity. RLFT involves collecting preference feedback from humans and training models to maximize rewards based on these preferences.
Tsinghua University proposed an innovative method in their research paper – OpenChat. OpenChat is an innovative framework that enhances open-source language models using mixed-quality data. At its core lies the Conditioned Reinforcement Learning Fine-Tuning (C-RLFT), a novel training method that simplifies the training process and reduces the reliance on reward models.
C-RLFT enriches the input information for language models by distinguishing between different data sources based on their quality. This distinction is achieved through the implementation of a class-conditioned policy. The policy helps the model differentiate between expert-generated data (of high quality) and sub-optimal data (lower quality). By doing so, C-RLFT provides explicit signals to the model, enabling it to improve its instruction-following abilities.
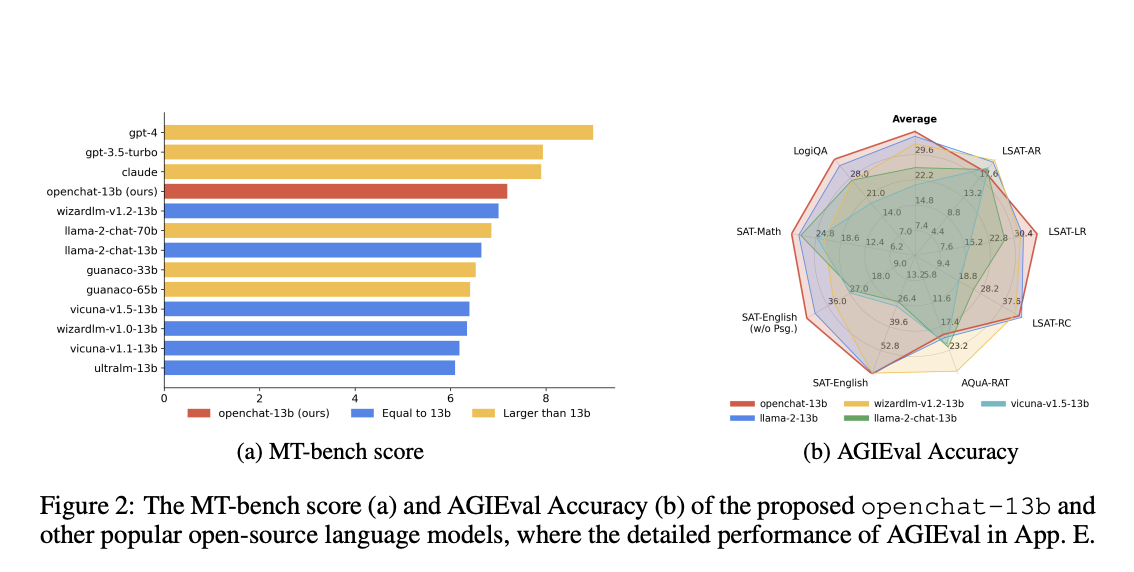
The performance of OpenChat, specifically the open chat-13 b model, has been evaluated across various benchmarks. One of the notable benchmarks used is AlpacaEval, where the model’s instruction-following abilities are put to the test. Openchat-13b exhibits remarkable results, outperforming other 13-billion parameter open-source models like LLaMA-2. It achieves higher win rates and superior performance in instruction-following tasks, demonstrating the effectiveness of the C-RLFT method.
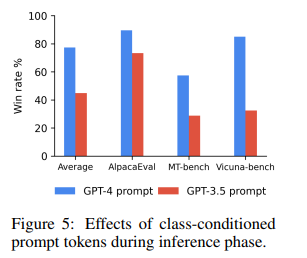
The significance of data quality is an important aspect highlighted by the research team. Despite its limited quantity, expert data plays a crucial role in enhancing the performance of language models. The ability to differentiate between expert and sub-optimal data, coupled with the C-RLFT method, leads to substantial improvements in model performance. This finding underscores the importance of curating high-quality training data to ensure the success of language model training.
Implications and Future Research
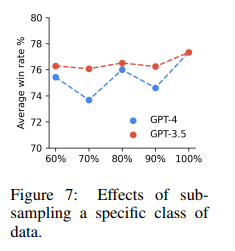
The OpenChat framework and the C-RLFT method hold promise for the future of natural language processing. This approach opens up new avenues for research and development by simplifying the training process and reducing reliance on complex reward models. It also addresses the challenge of mixed-quality data, making it more accessible to leverage diverse training datasets effectively.
In conclusion, OpenChat presents an innovative solution to enhance open-source language models with mixed-quality data. By introducing the C-RLFT method, this approach achieves superior instruction-following abilities, as evidenced by its performance in benchmarks. As natural language processing continues to evolve, innovative techniques like OpenChat pave the way for more efficient and effective language model training.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
